| 1D Travelling Wave | 2D Spherical Travelling Wave |
|---|---|
.gif) | 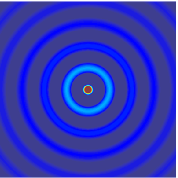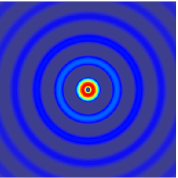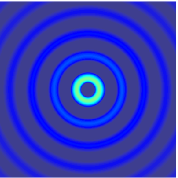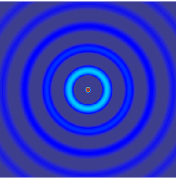 |
I explored the interesting topic of cortical traveling waves (TWs) during summer 2020 with the guidance of Prof. Sven Bestmann. I acquired a lot of new skills and gained new insights into the essence of oscillatory signals. Below is my first experiment about the detection of spherical TWs at a macroscopic scale.
Update: For my second (and more formal) experiment about planar TWs at mesoscopic scale, click here.
In this project, I tried to simulate an electrophysiological recording dataset (say, EEG) which contains cortical travelling waves. I spent most of my time on two questions:
Since the first problem might be too simple for experts, I'll put it in the discussion section and work on the second problem first.
In order to make the synthetic data more similar to real EEG recordings, we decided to construct the signal in frequency domain, with a "reference" power spectrum (computed from a long resting EEG dataset) and a phase spectrum that we can manipulate.
Initially, we decided to simulate a wave that travels on a line, from center (Cz) to front/back/left/right (Fpz/Oz/T7/T8). Therefore, we:
Here the constant phase lag is linear to the distance between the channel and Cz, as well as the central frequency in each band (namely, the waves travel at a fixed speed - about 5m/s according to the literature).
The codes can be downloaded here.
The simulation above is based on the assumption that the wave carries specific information that must be conveyed to a certain area. But actually the two-dimensional spherical travelling wave is more common in electrophysiological recording:
| 1D Travelling Wave | 2D Spherical Travelling Wave |
|---|---|
| |
Therefore, we created another dataset with spherical TWs in the same way as we described before, except that the constant phase lag became
The codes can be downloaded here.
Here is what we got:
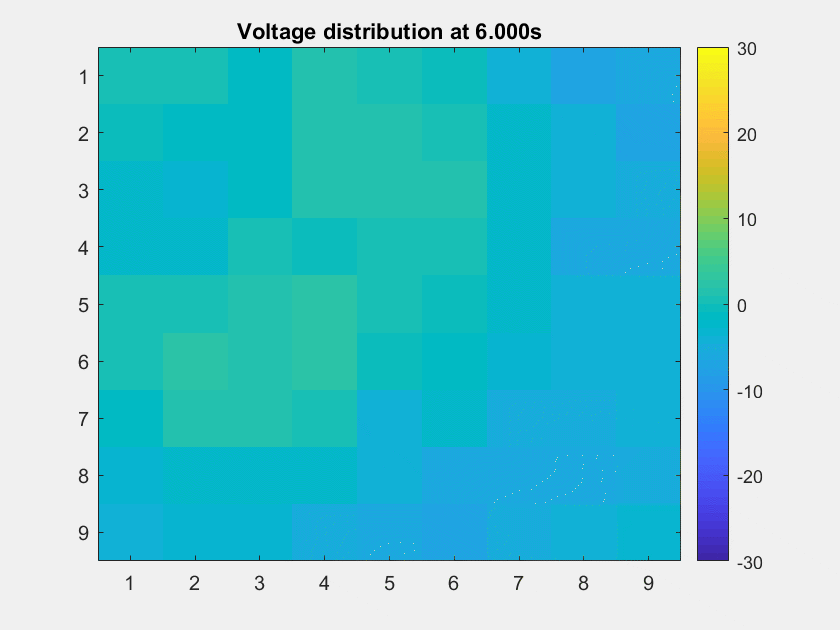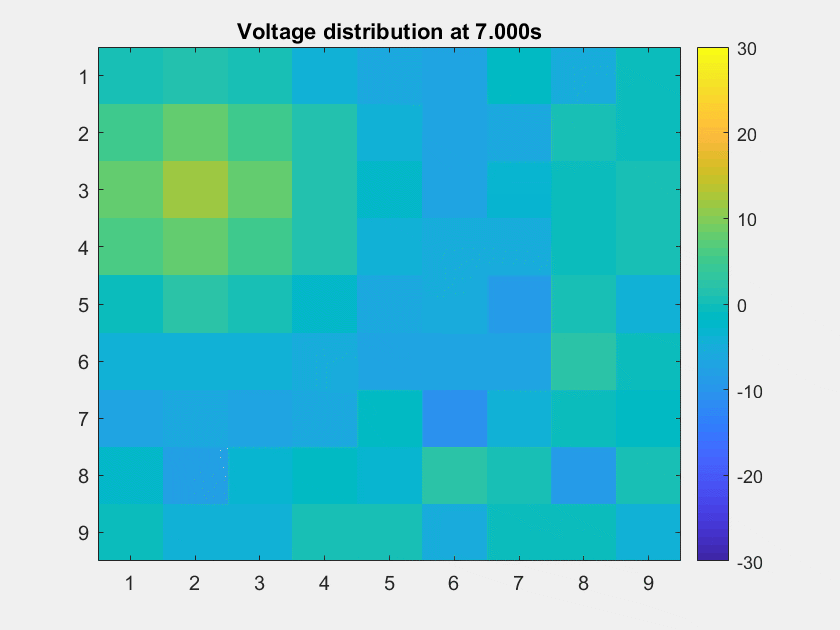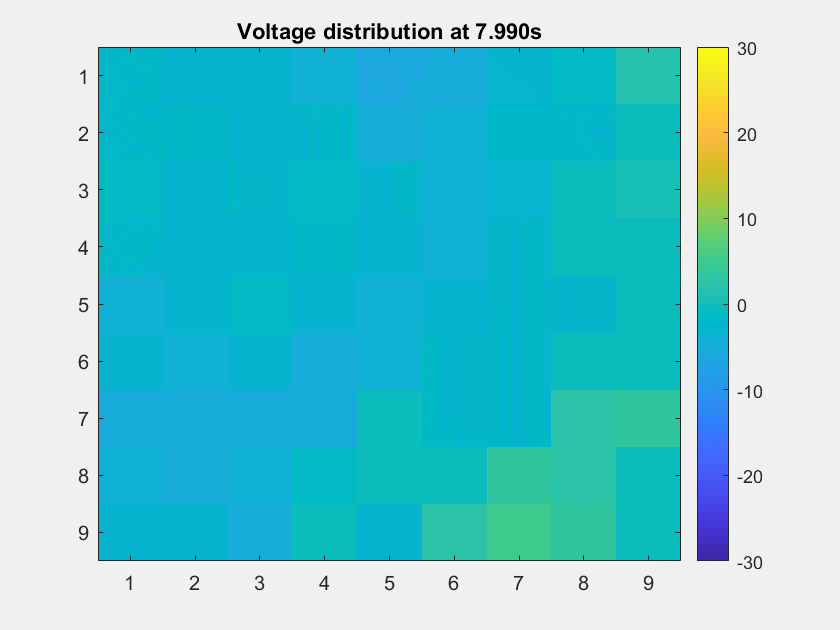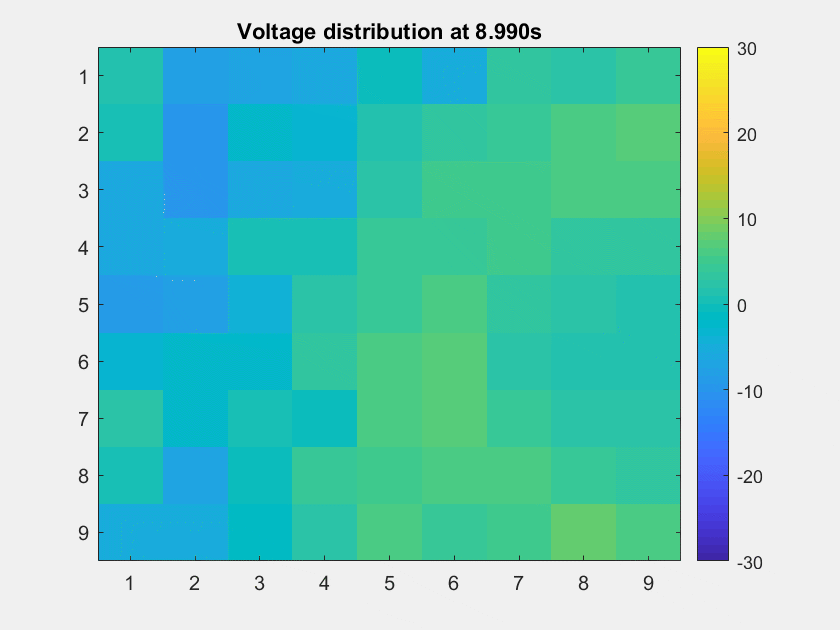
The voltage distribution is mostly consecutive. Here is the phase distribution:
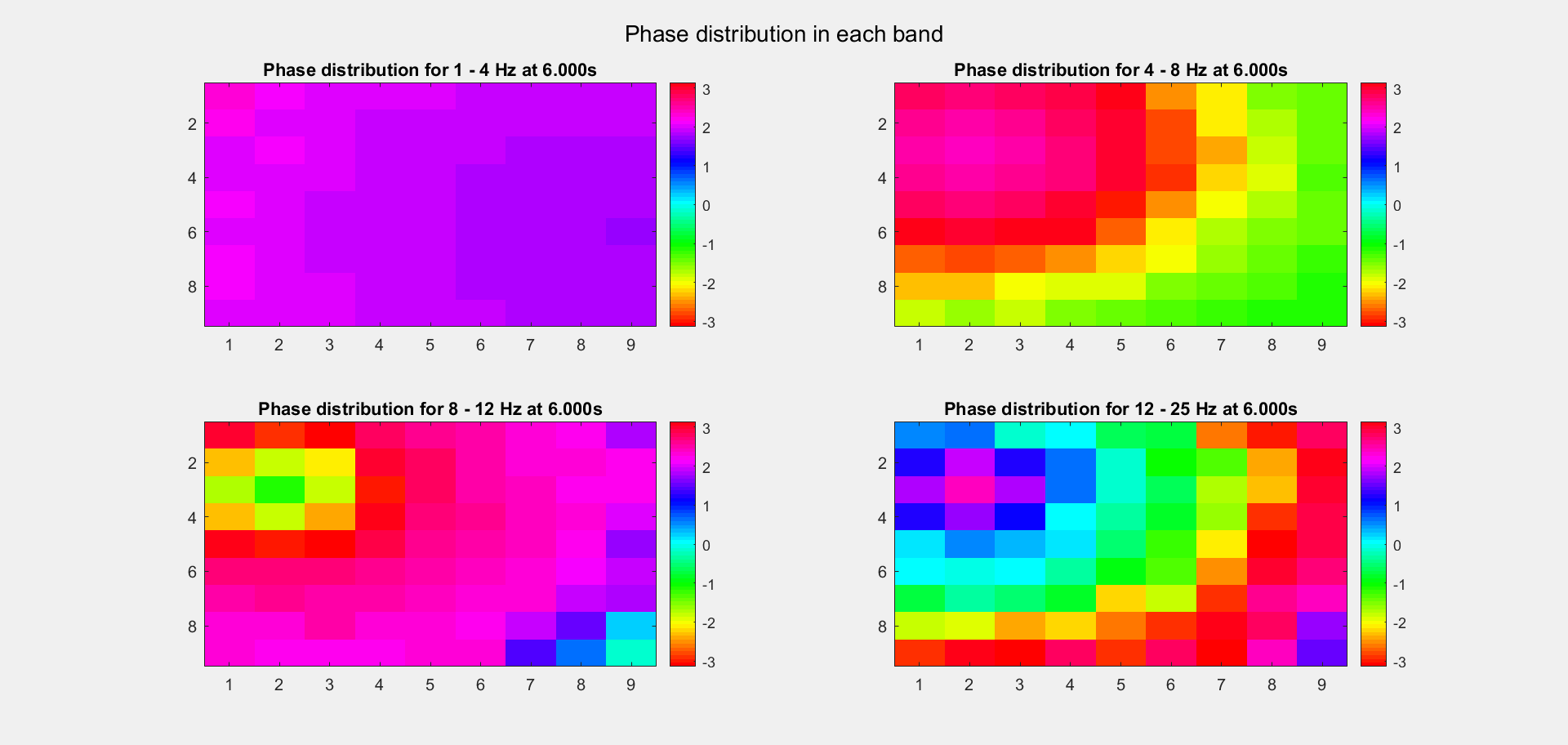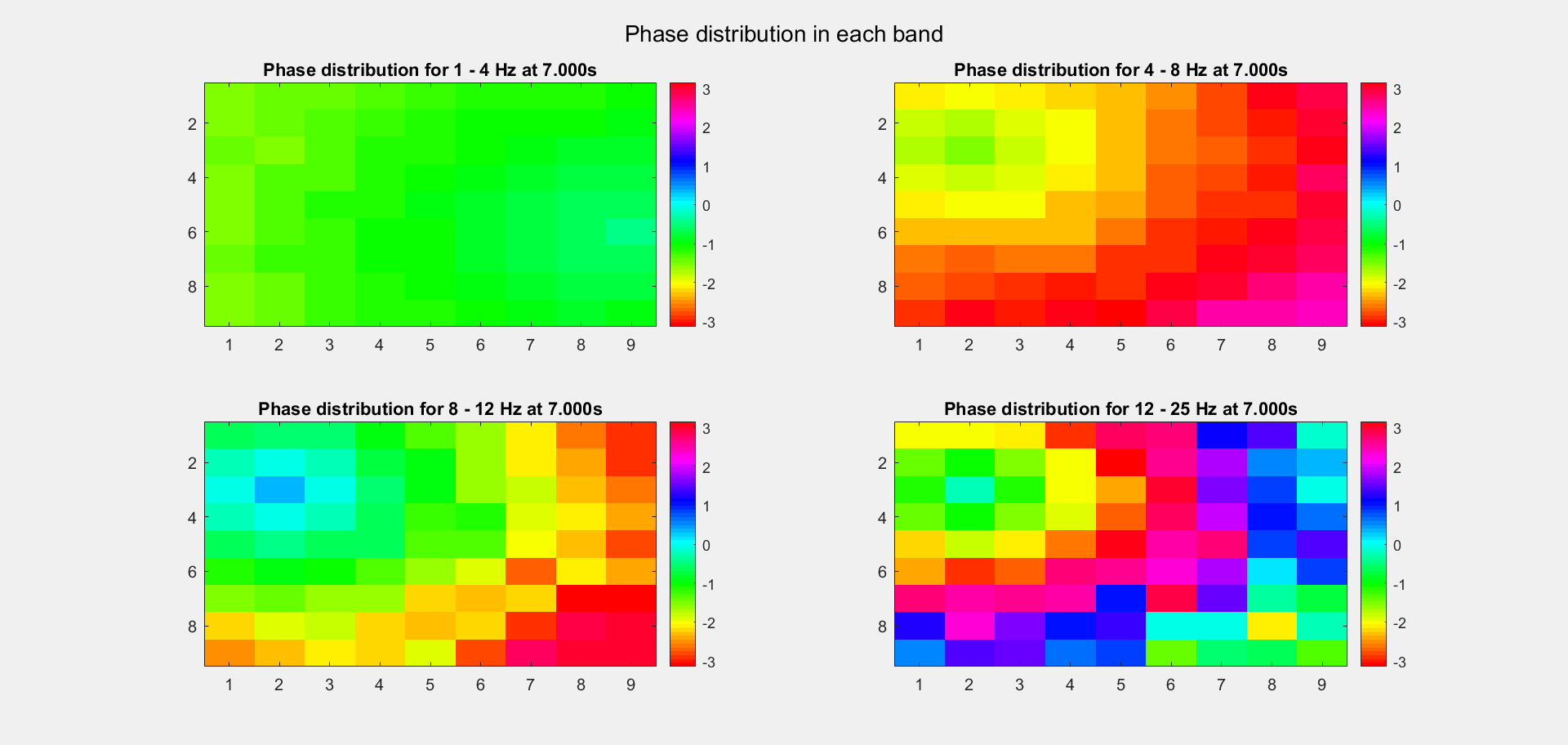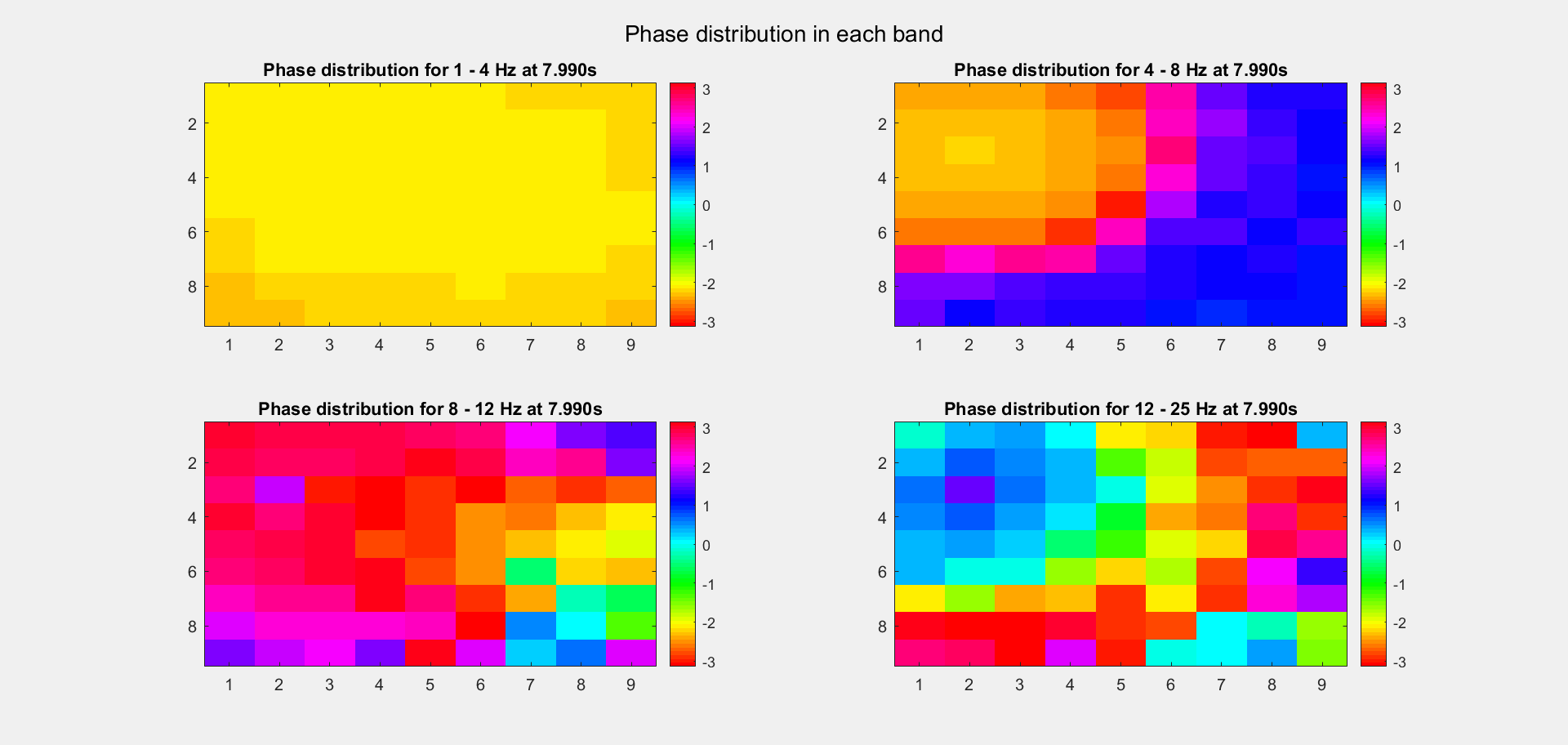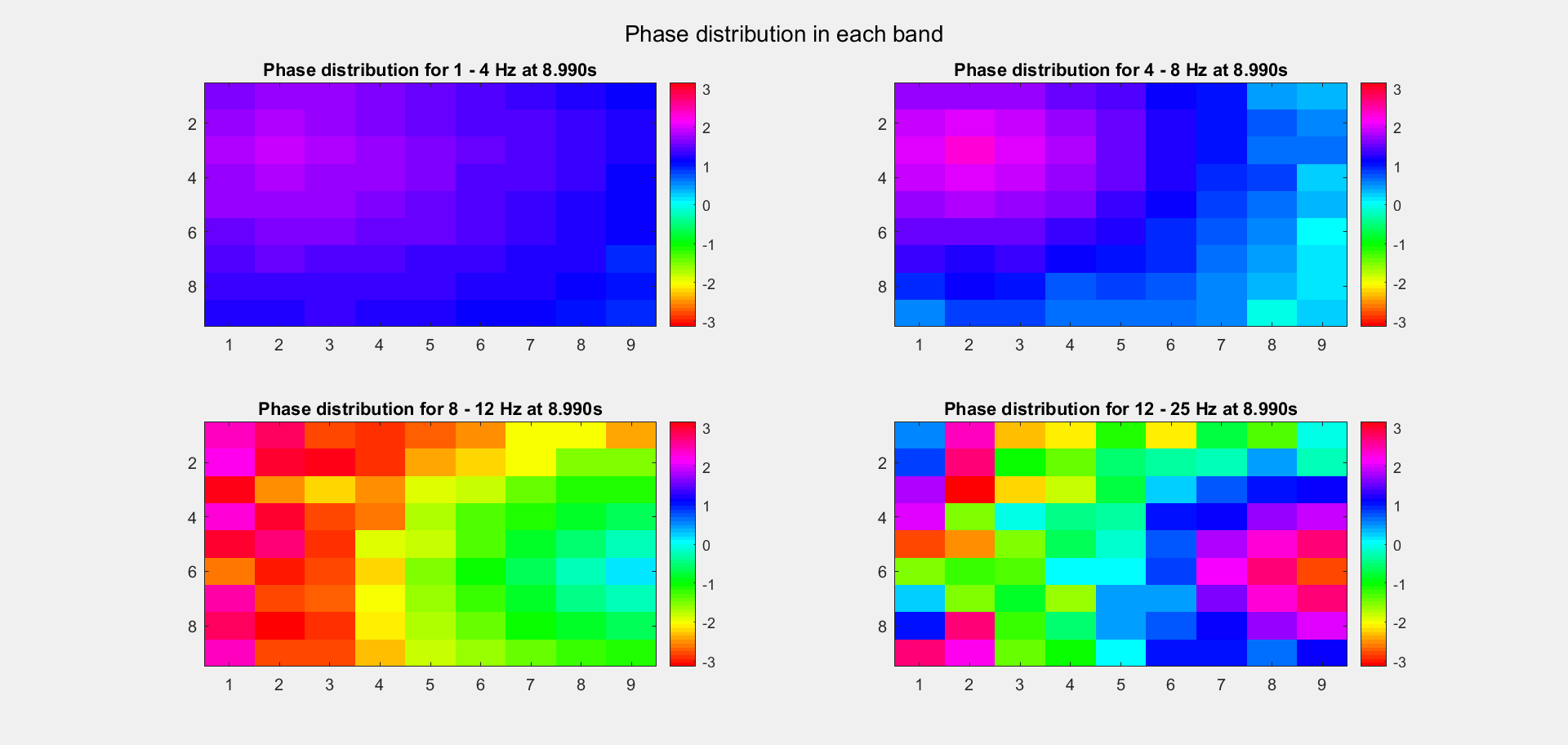
Finally, let's compare the voltage sequence and oscillatory power of our data and the reference data:
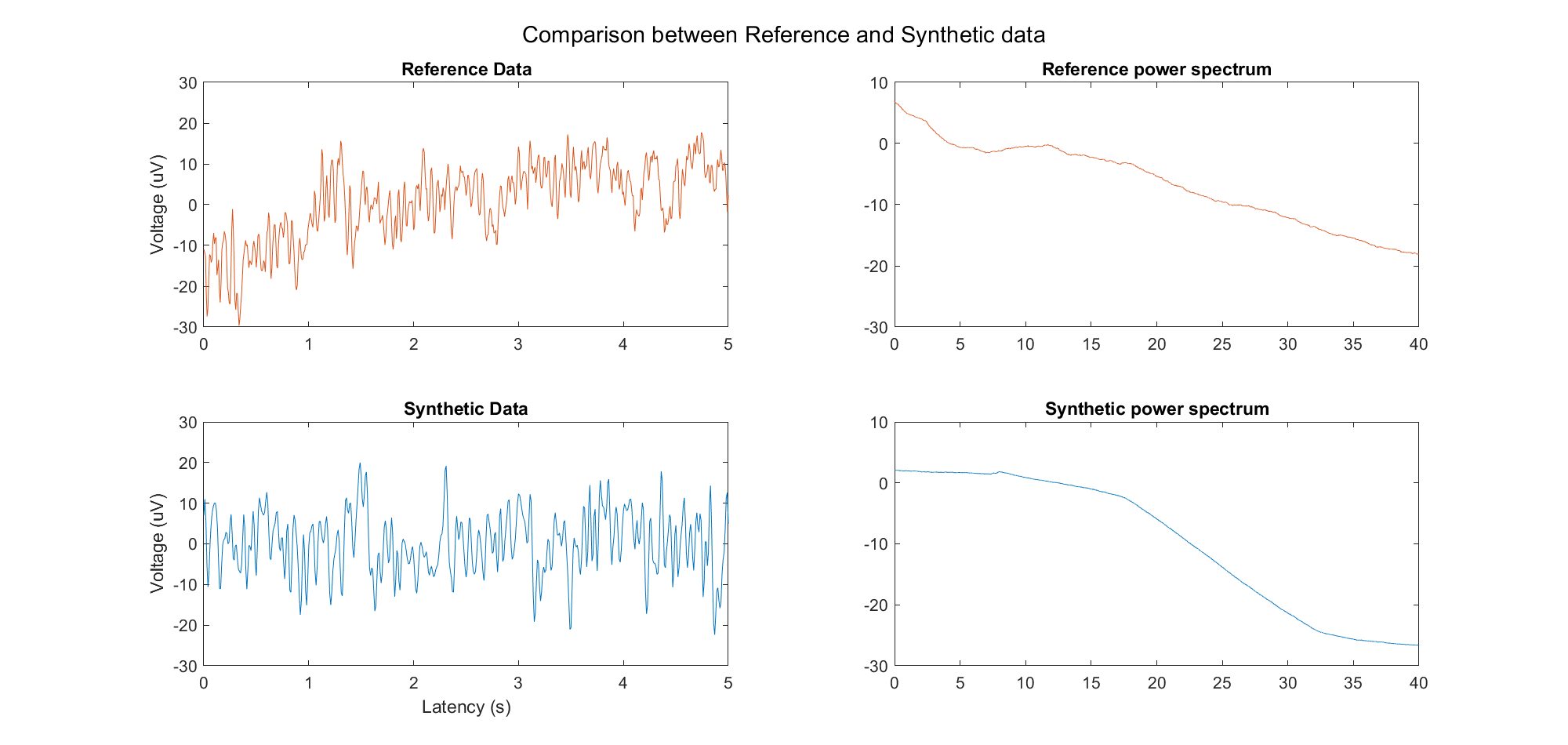
This is a non-TW channel at the corner, and the simulated data looks quite acceptable. Note that we only add up the delta/theta/alpha/beta band (from 1-25Hz) so the high frequency band is weak.
After simulating an EEG dataset with traveling wave, we analyzed this dataset with different algorithms. We implemented the methods in (Alexander et. al., Plos One, 2016) and (Alexander et. al., Plos Comput. Biol., 2019). For each frequency-of-interest, the first one uses k-means algorithm to cluster the phase evolution within every cycle (i.e. the input vector length is
Following (Alexander et. al., Plos One, 2016), we want to cluster the individual data cycles so that each cluster represents an unique TW with a certain source s.
For each frequency (from 1 to 32, log-spaced) and each cycle:
Compute the wavelet coefficients (at each time point, for each channel) as an estimation of STFT components, using very short Morlet wavelet.
cmorwavf(LB, UB, N, FB, FC), we let Extract the real-value angles as a nPWin*nChn matrix m.
(Optional) Remove the common phase offset from m, either by subtracting m(1, 1) or mean(m(:,1))
Then:
Vectorize these matrices and use k-means to get k cluster centers.
evalclusters() to determine the optimal k (ranging from 3 to 8) with Silouette criterionSpatially unwrapped the phases by nearest neighbour edges.
Approximate these k patterns by a spherical wave (with the same temporal frequency as the current wavelets), minimizing the square error
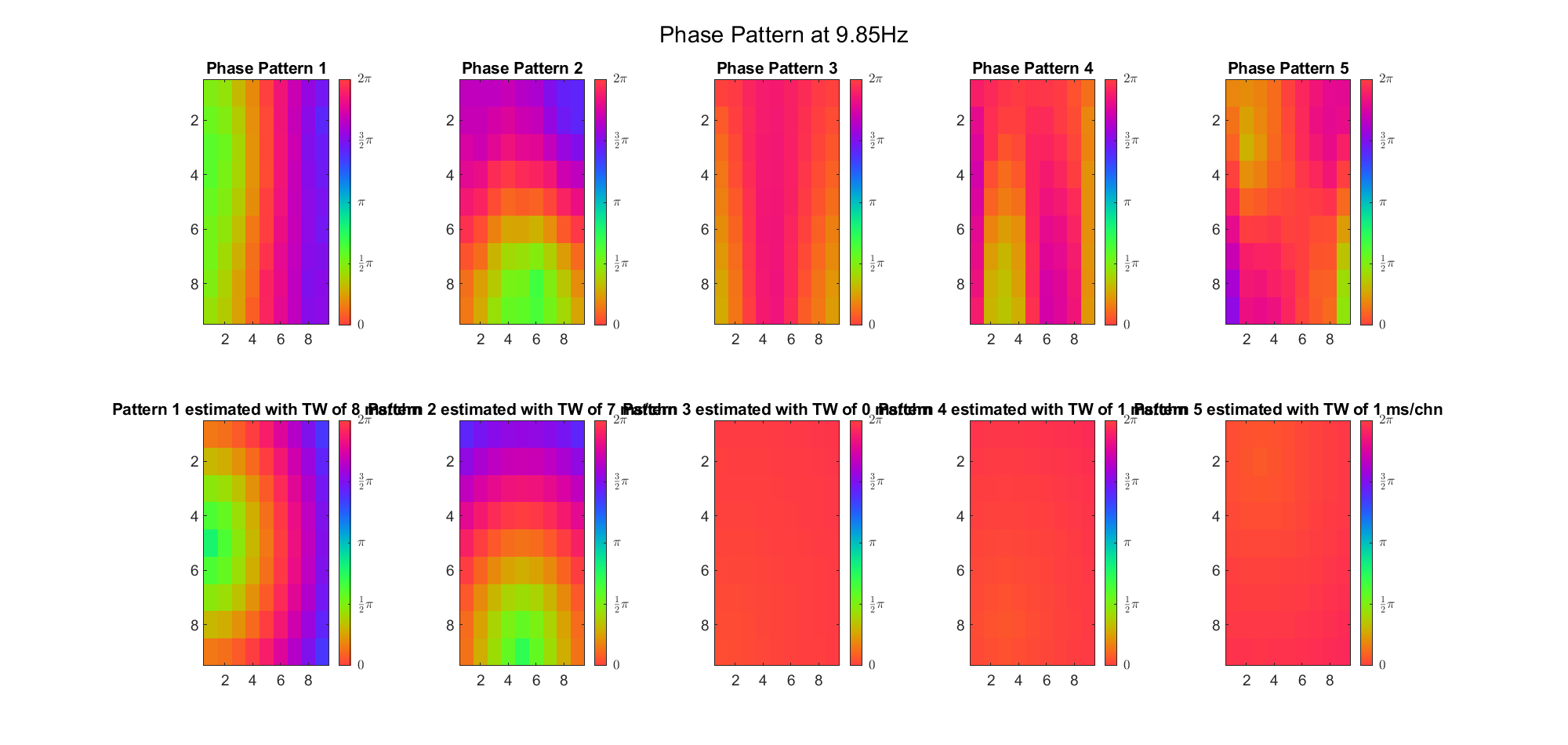
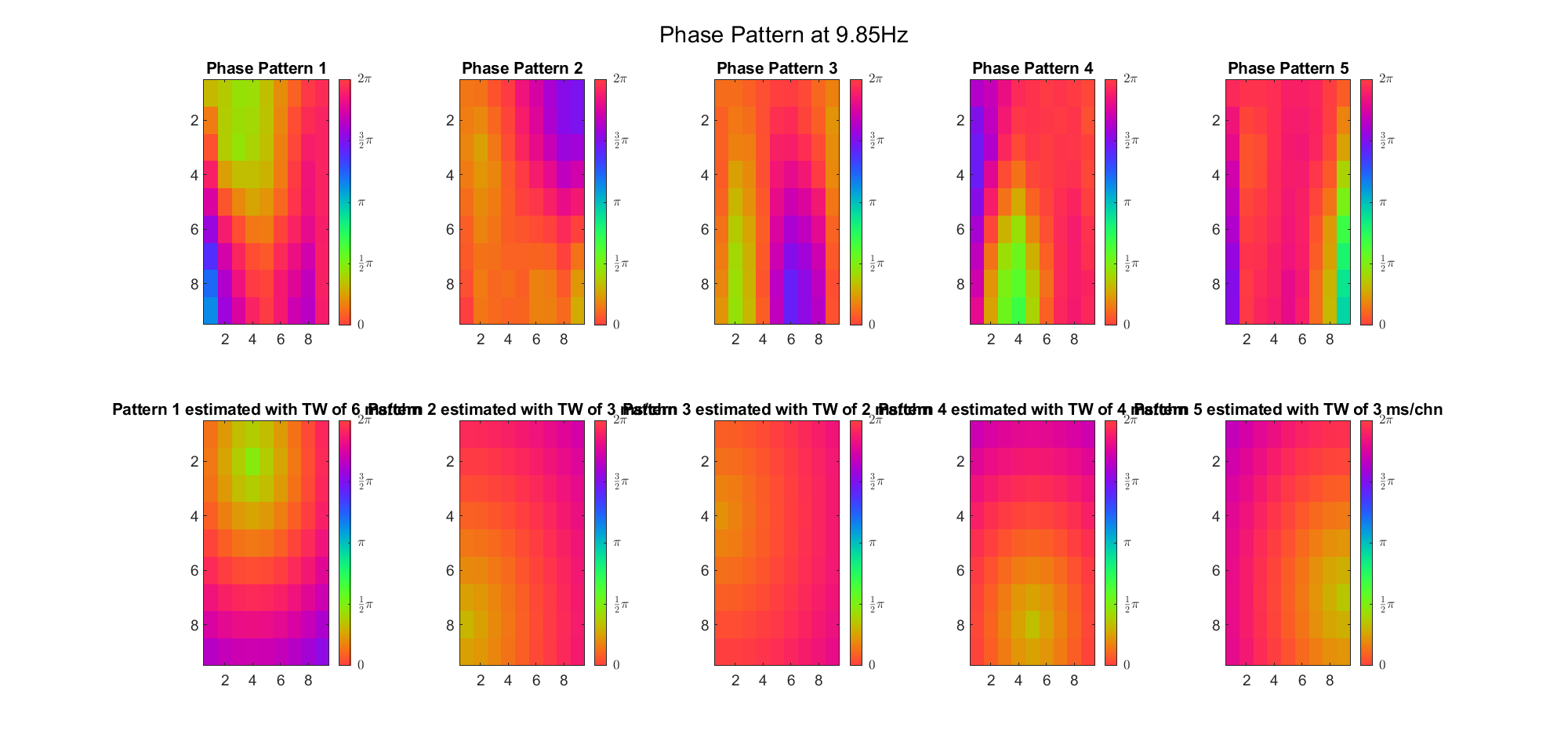
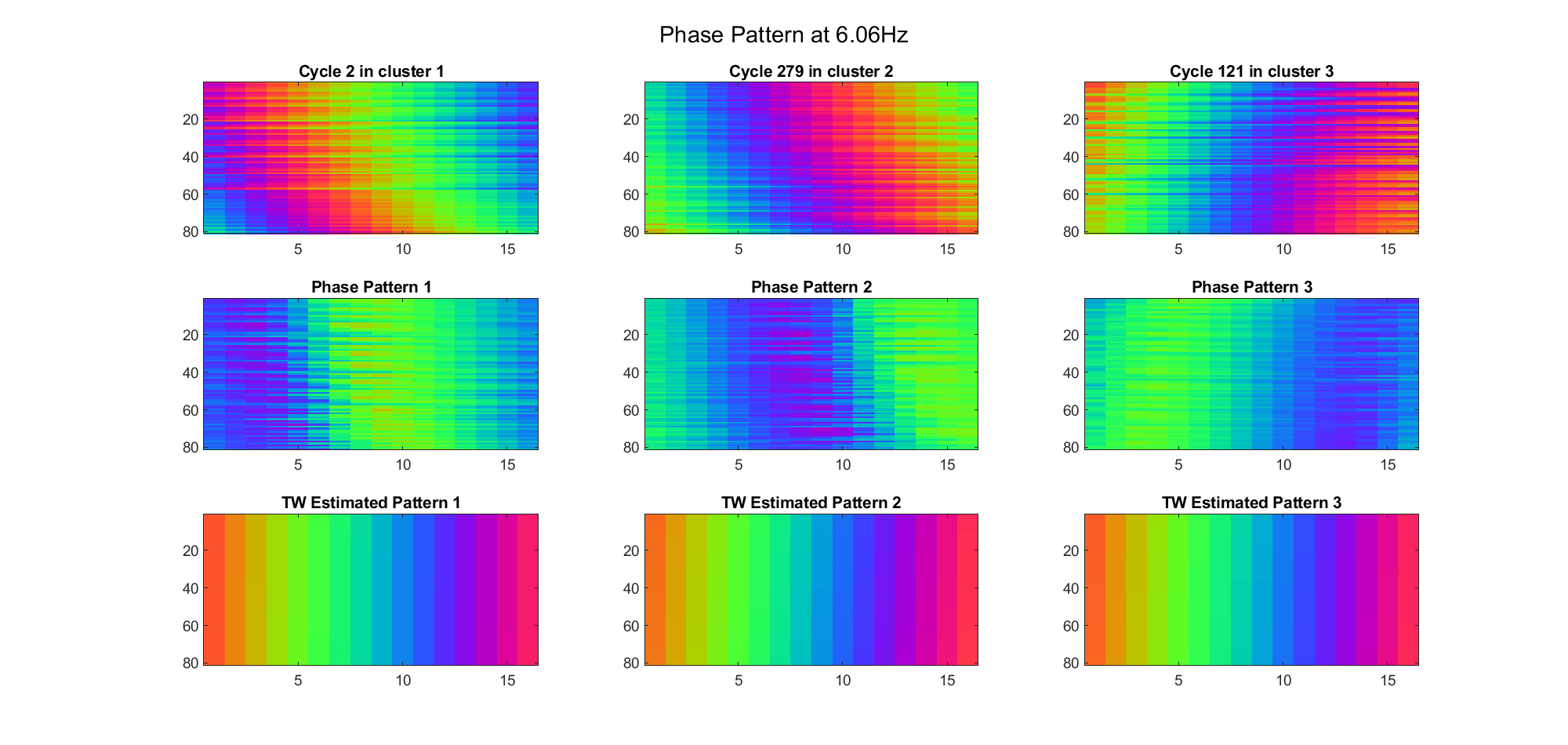
First we examined the result in time domain, channels (1-81) aligned by the estimated TW's initial phases in ascending order:
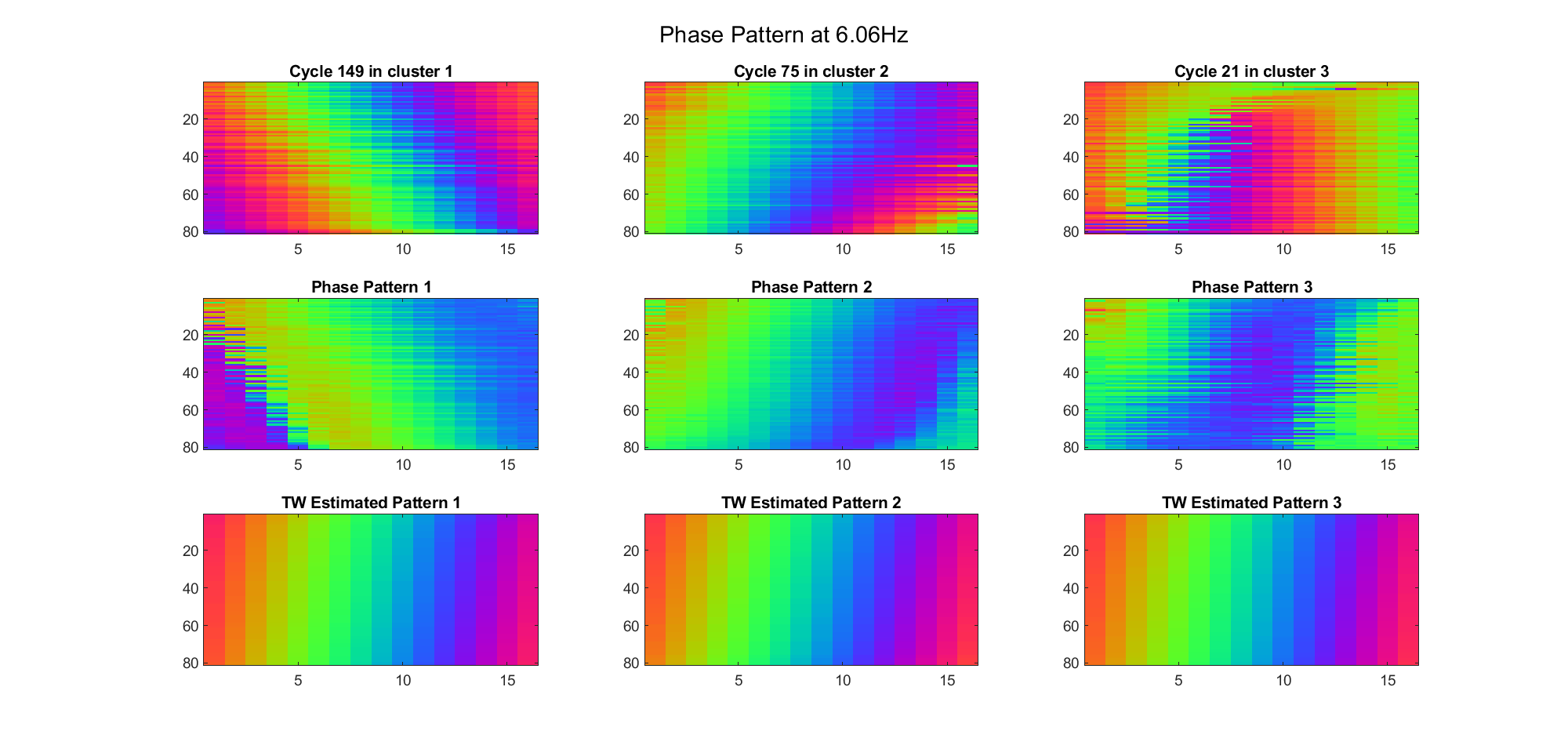
We can see that:
We also tried what would happen if the temporal frequency
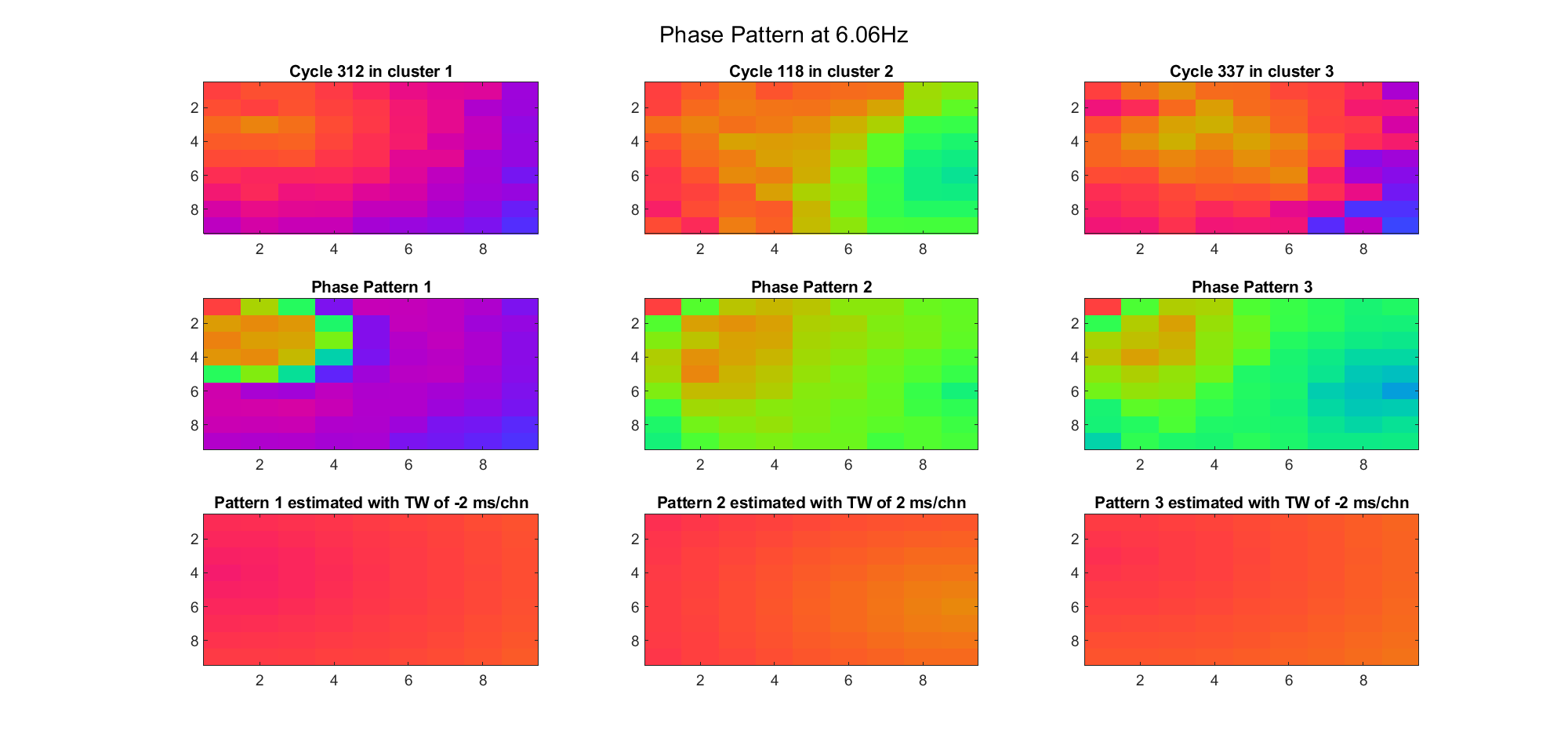
(Note: the ground truth is that there were two possible sources, (3, 2) as in cycle 312 and (6, 9) as in cycle 118; and the speed of the TW was 7ms/chn; same below)
Due to the clustering error, the phase pattern didn't resemble a 6.06Hz wave in time, so there was a large overall phase difference between the pattern and underlying TW at every time point (e.g., the mean value of the estmated TW in the third row was completely different from that of the patterns in the second row). So it's quite hard to correctly estimate the source and spatial frequency of the TW.
Fortunately, we can see that the averaged patterns are basically consistent with the individual cycles, so we may be able to find the correct TW by another linear regression after subtracting mean(m, 1) from m. But if so, why not just perform k-means on data samples rather than the whole cycle? Therefore, we tried two different methods to find the structure from data samples directly.
As is described in (Alexander et. al., Plos Comput. Biol.), this method is quite straightforward. We organized the phases (unlike the original paper, we used the real-value phases rather than complex exponentials) into an
A very difficult problem is how to scale the principle components. We tried to multiply each component by the data samples' highest / 5% highest / mean projection on them, and it seems that the second one approximated the real spatial frequency best. Besides, this time we constrained the spatial frequency to be positive in the TW model during linear regression.
Here's the result for theta band (ground truth is still (3, 2) and (6, 9) and 7ms/chn):
| Before Rotation | VariMax Rotation | |
|---|---|---|
| With Offset | 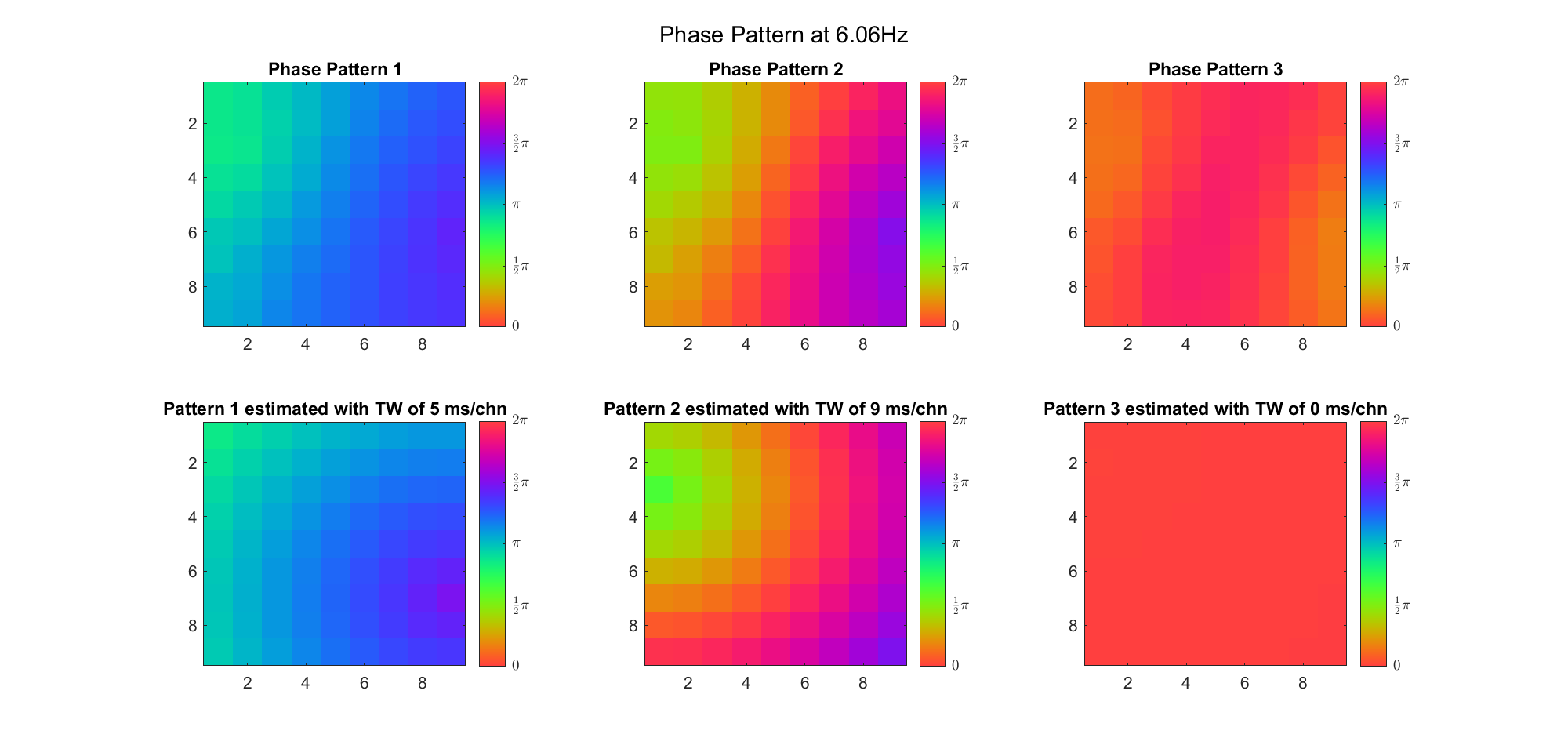 | 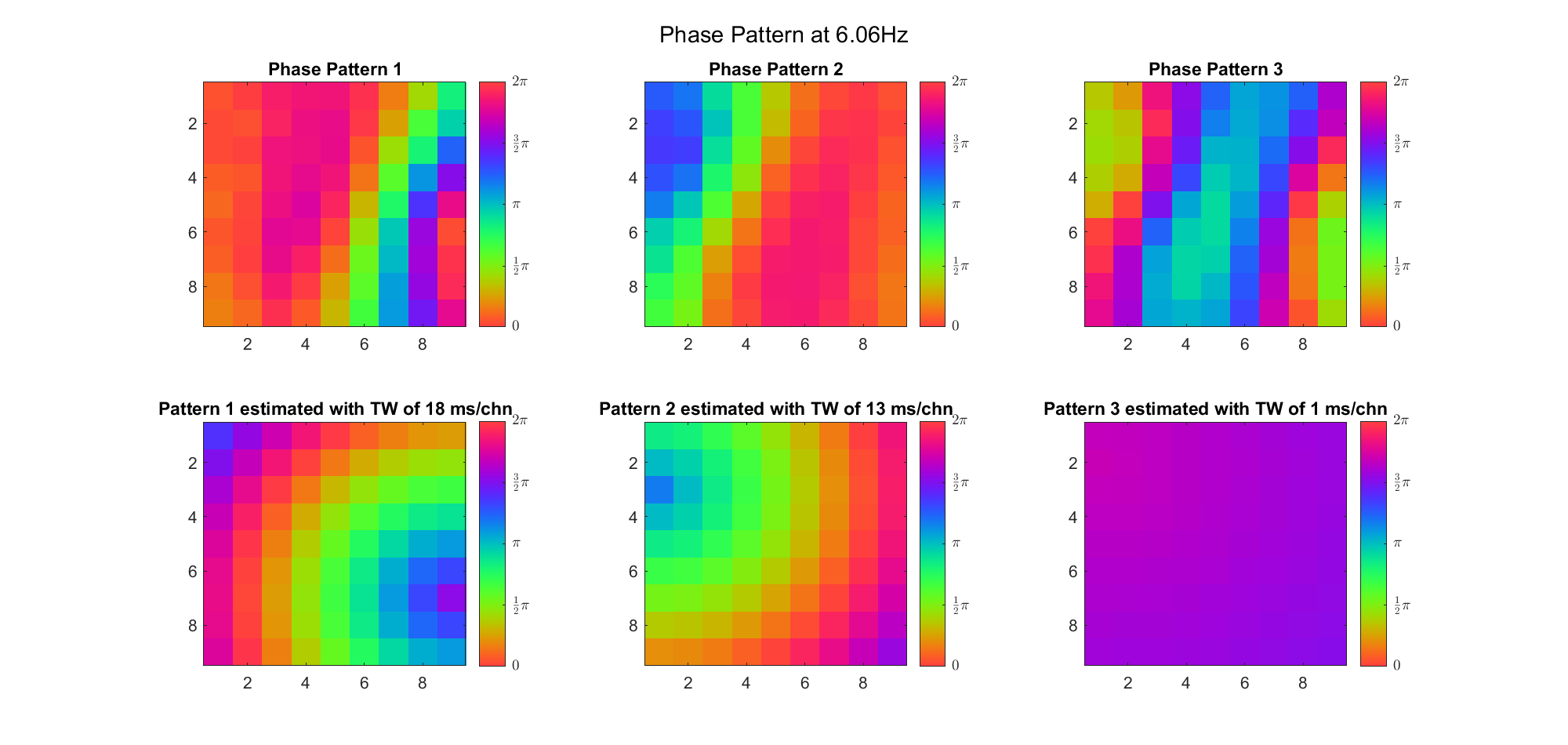 |
| Remove Offset | 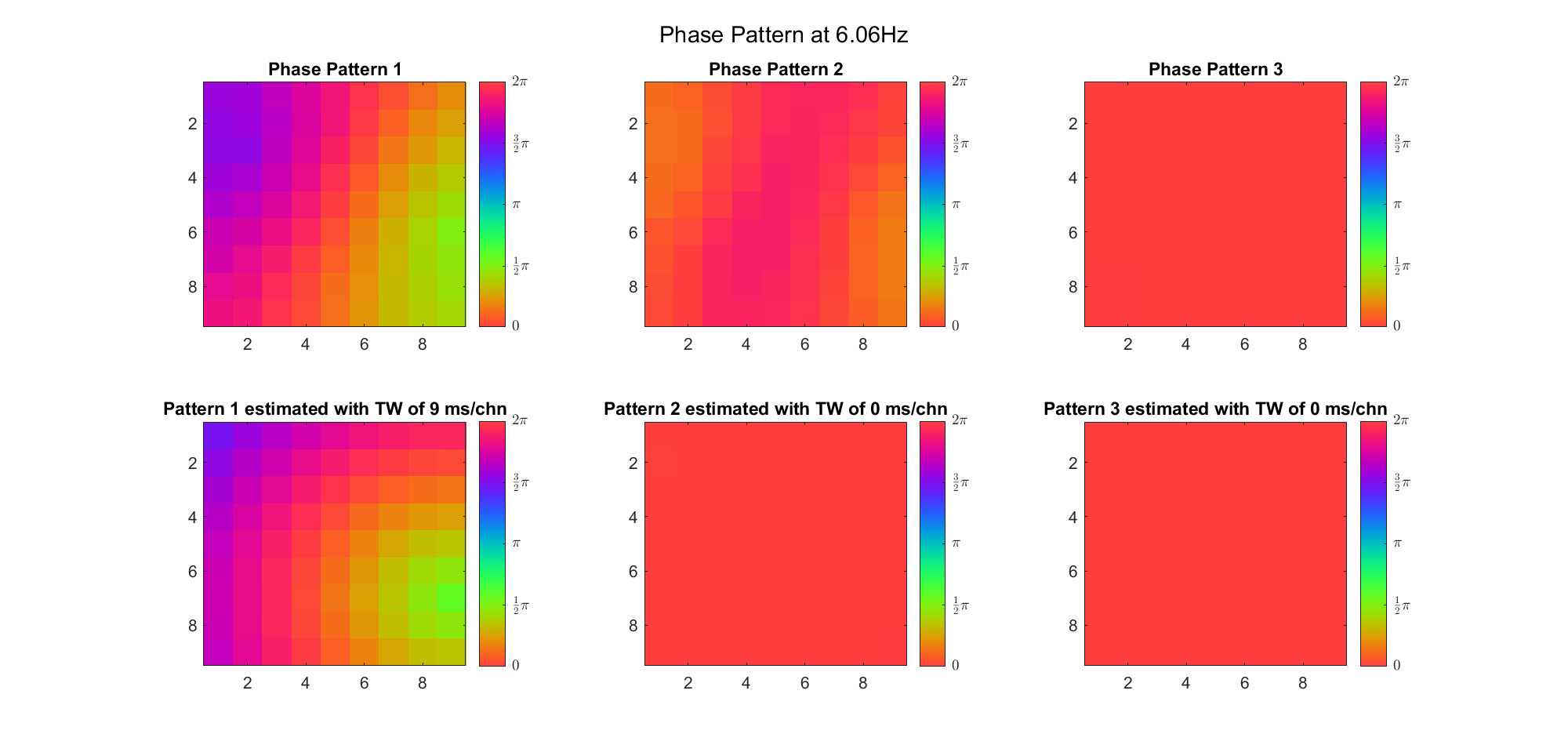 | 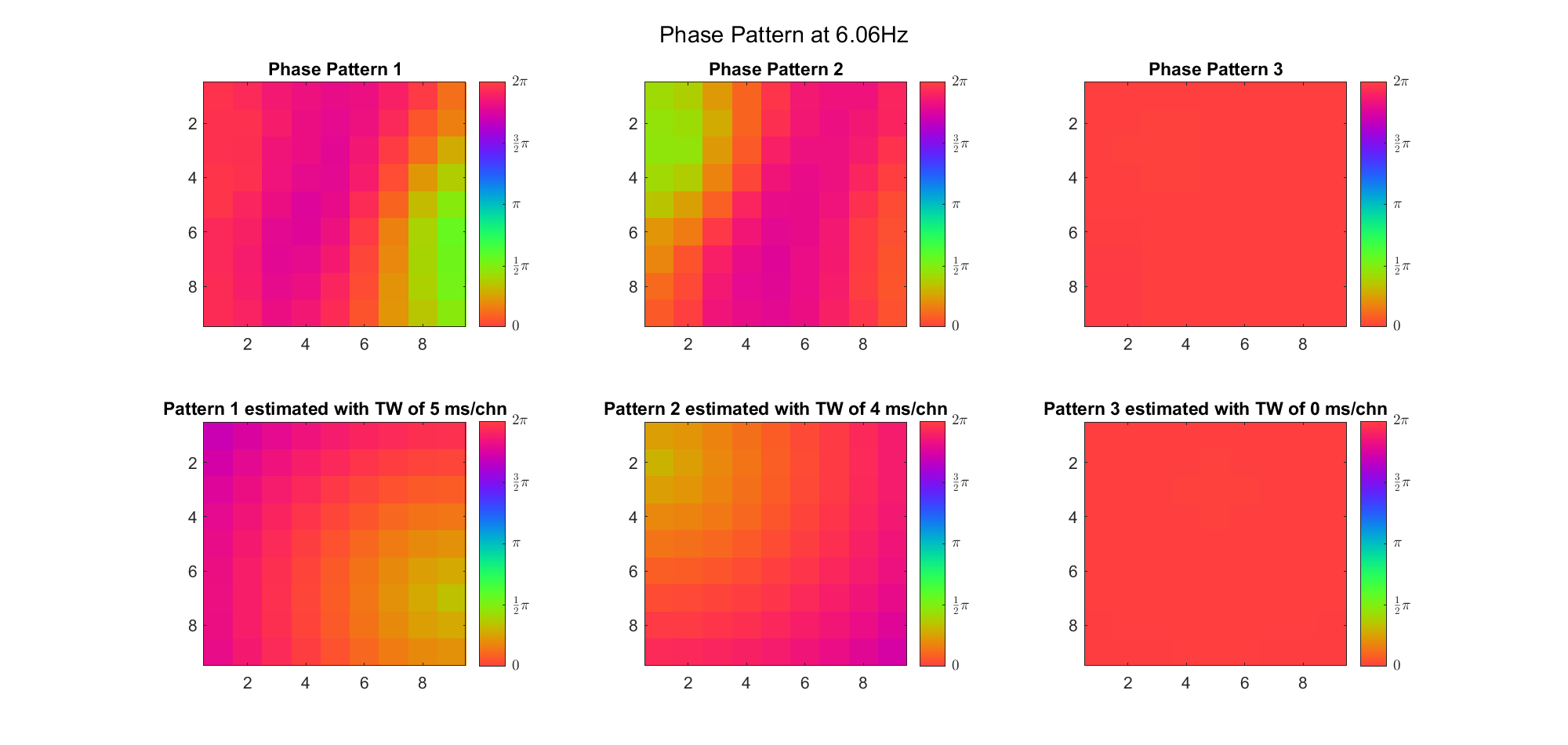 |
For alpha band:
| Before Rotation | VariMax Rotation | |
|---|---|---|
| With Offset | 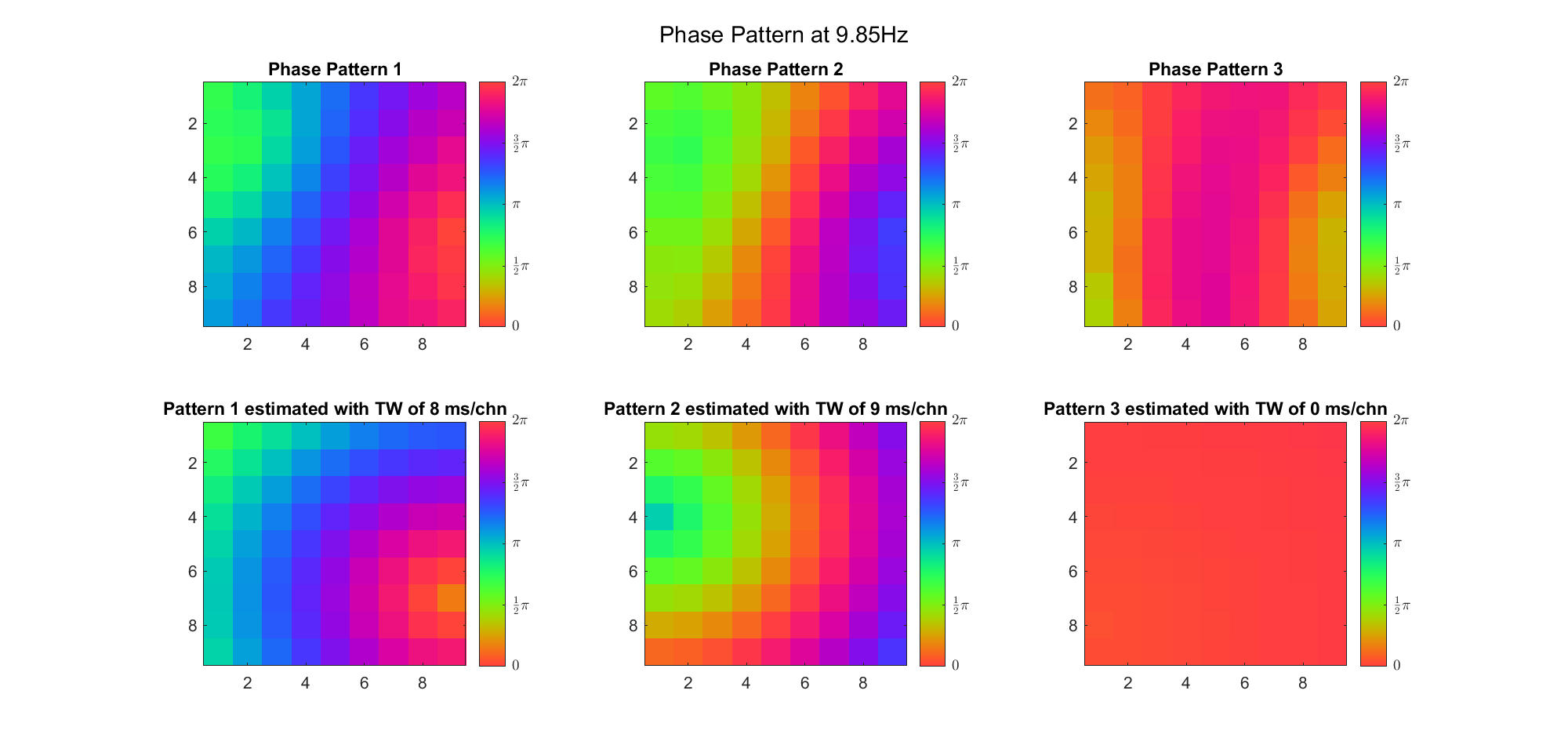 | 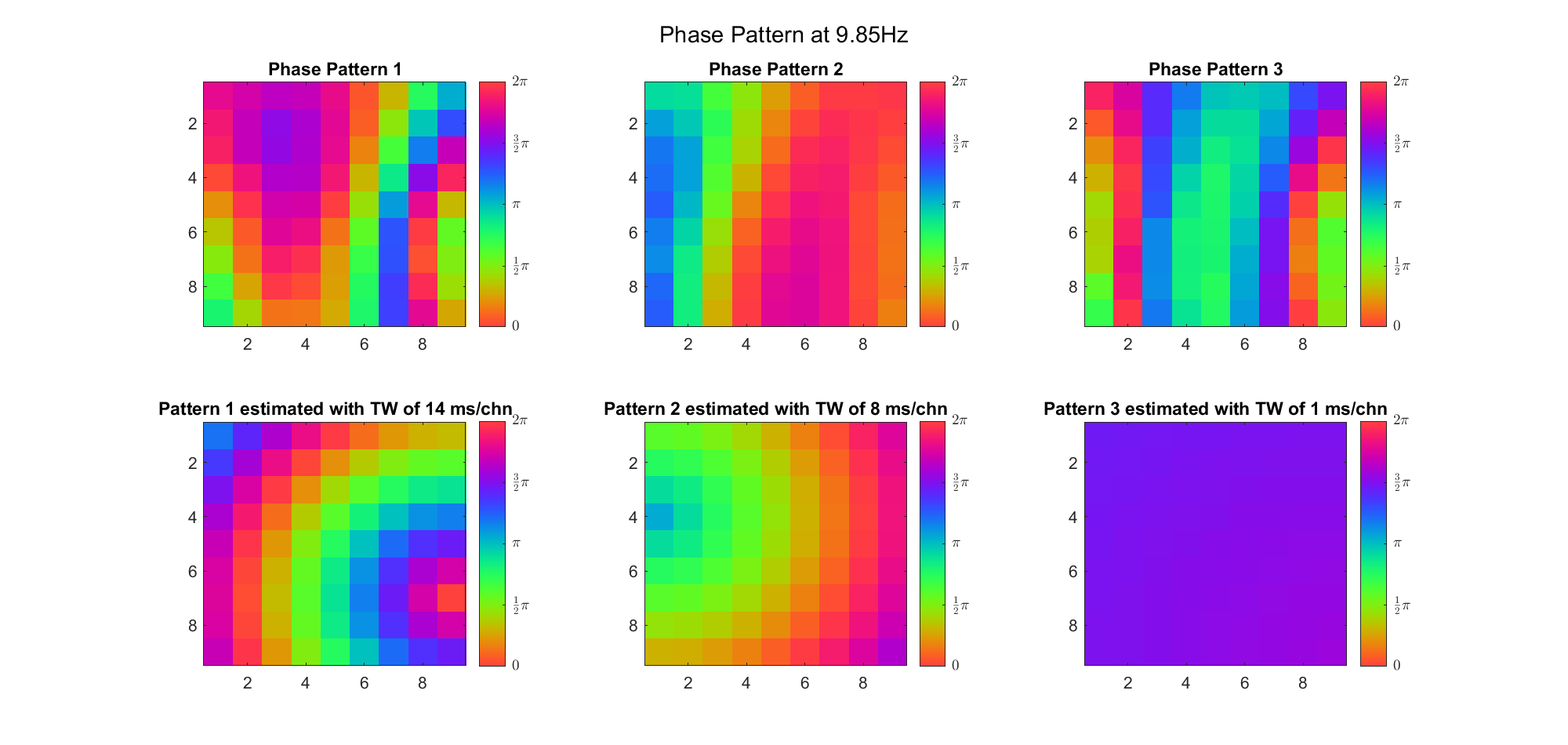 |
| Remove Offset | 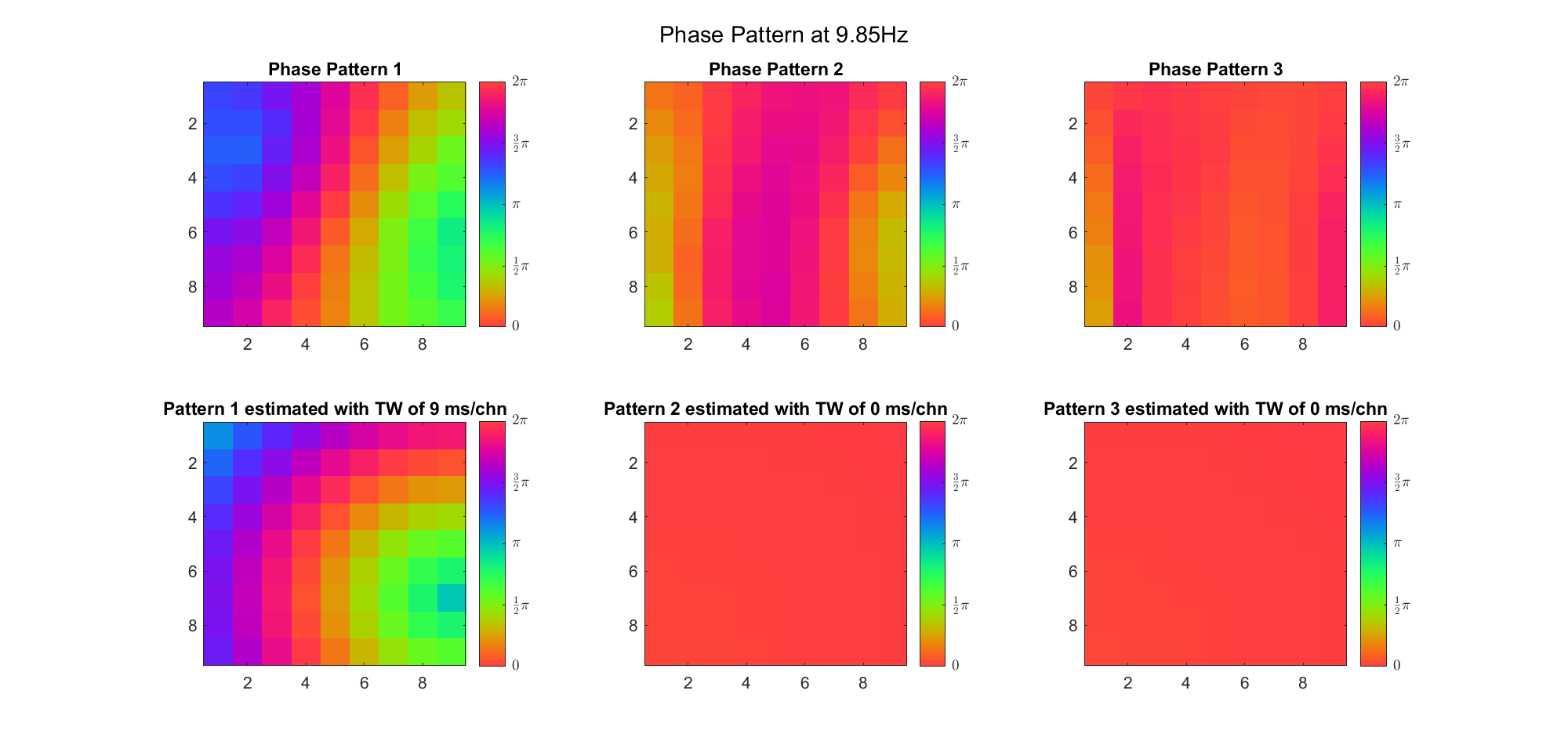 | 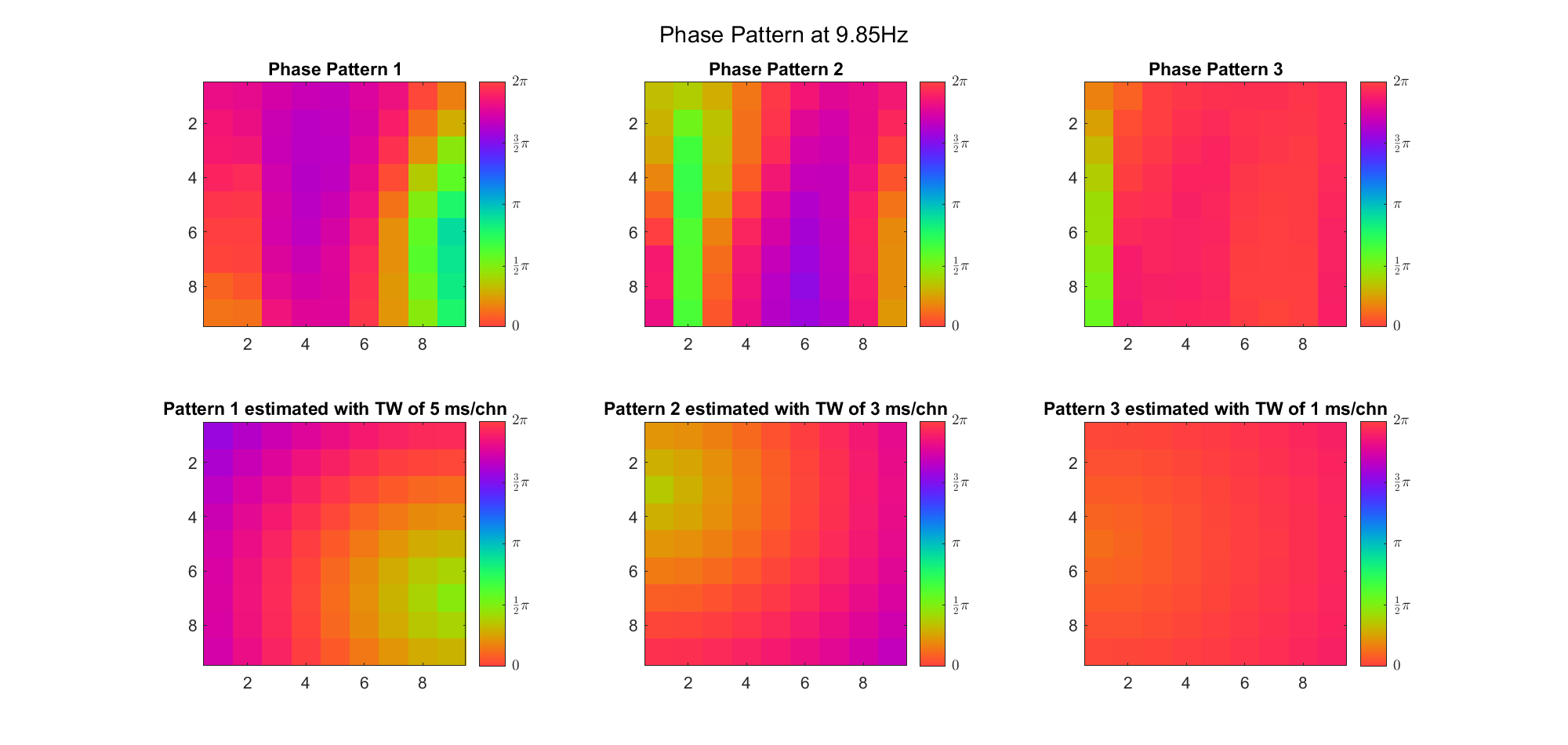 |
For beta band:
| Before Rotation | VariMax Rotation | |
|---|---|---|
| With Offset | 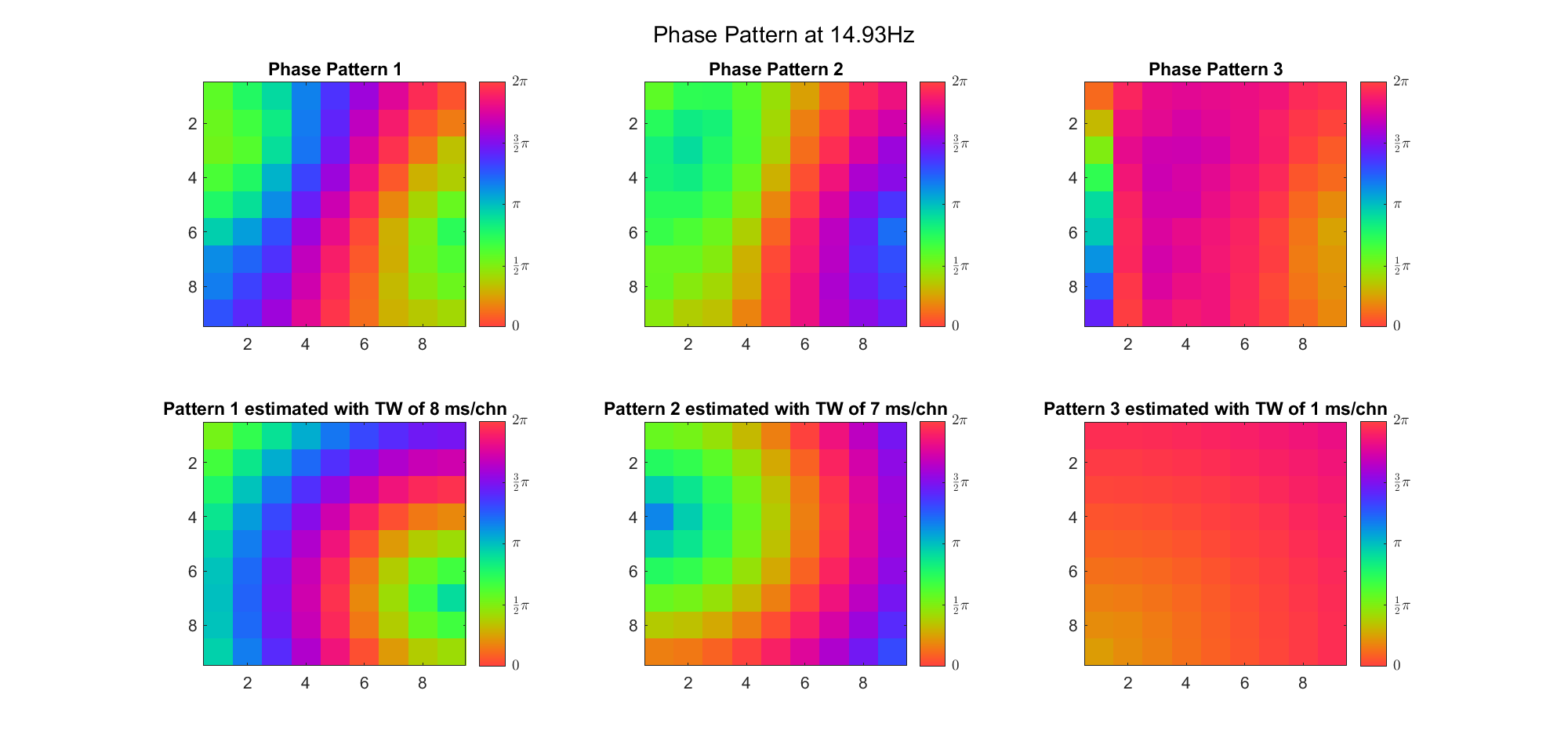 | 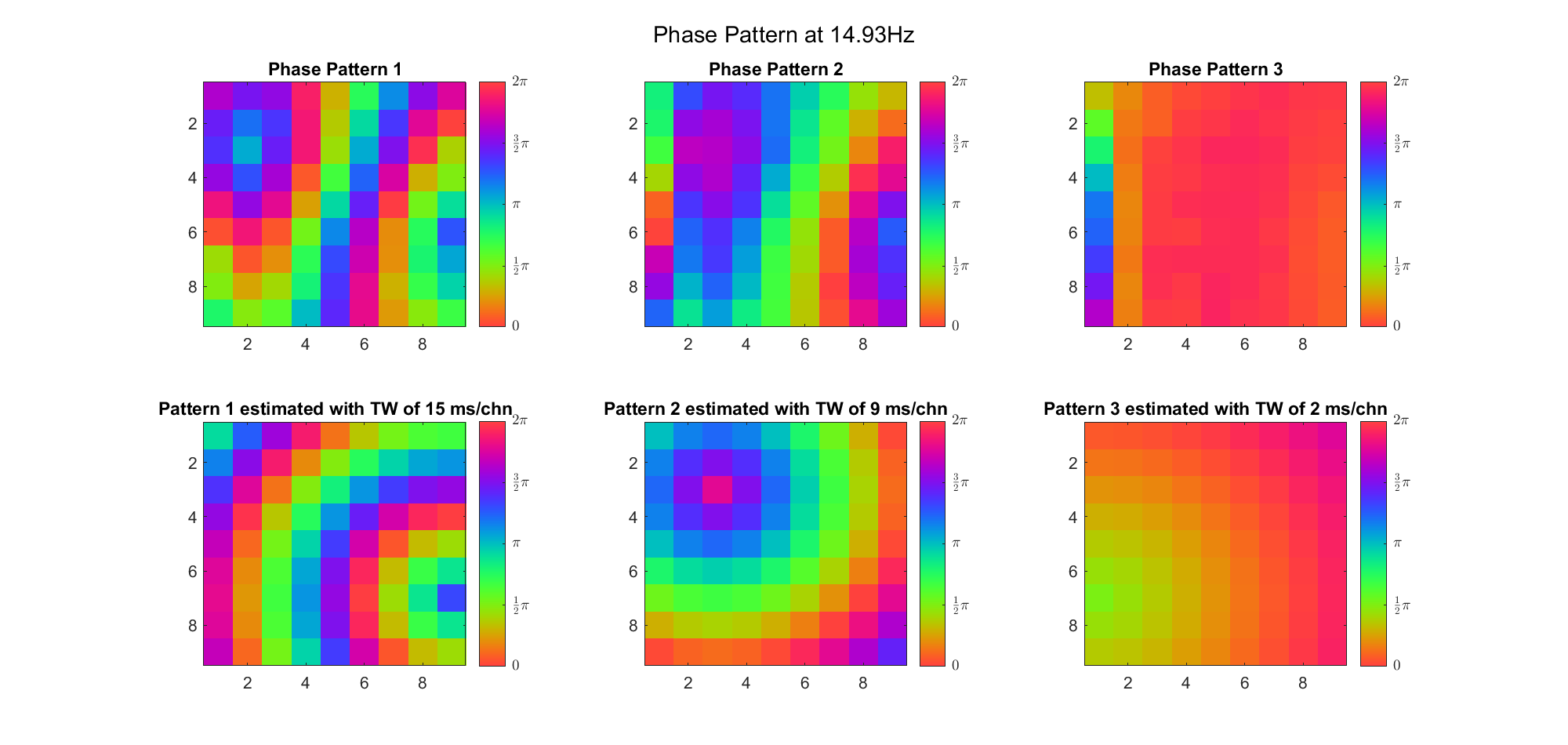 |
| Remove Offset | 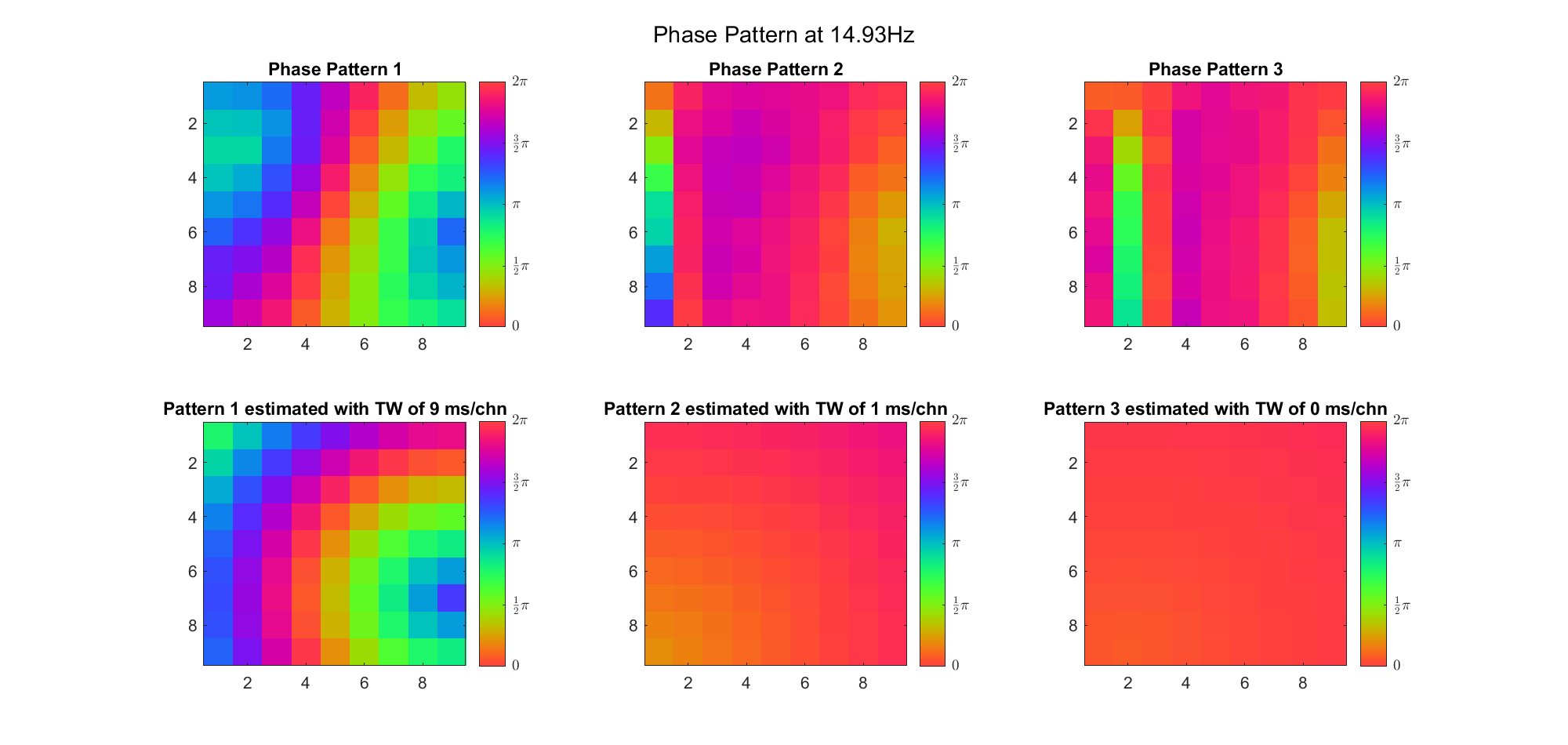 | 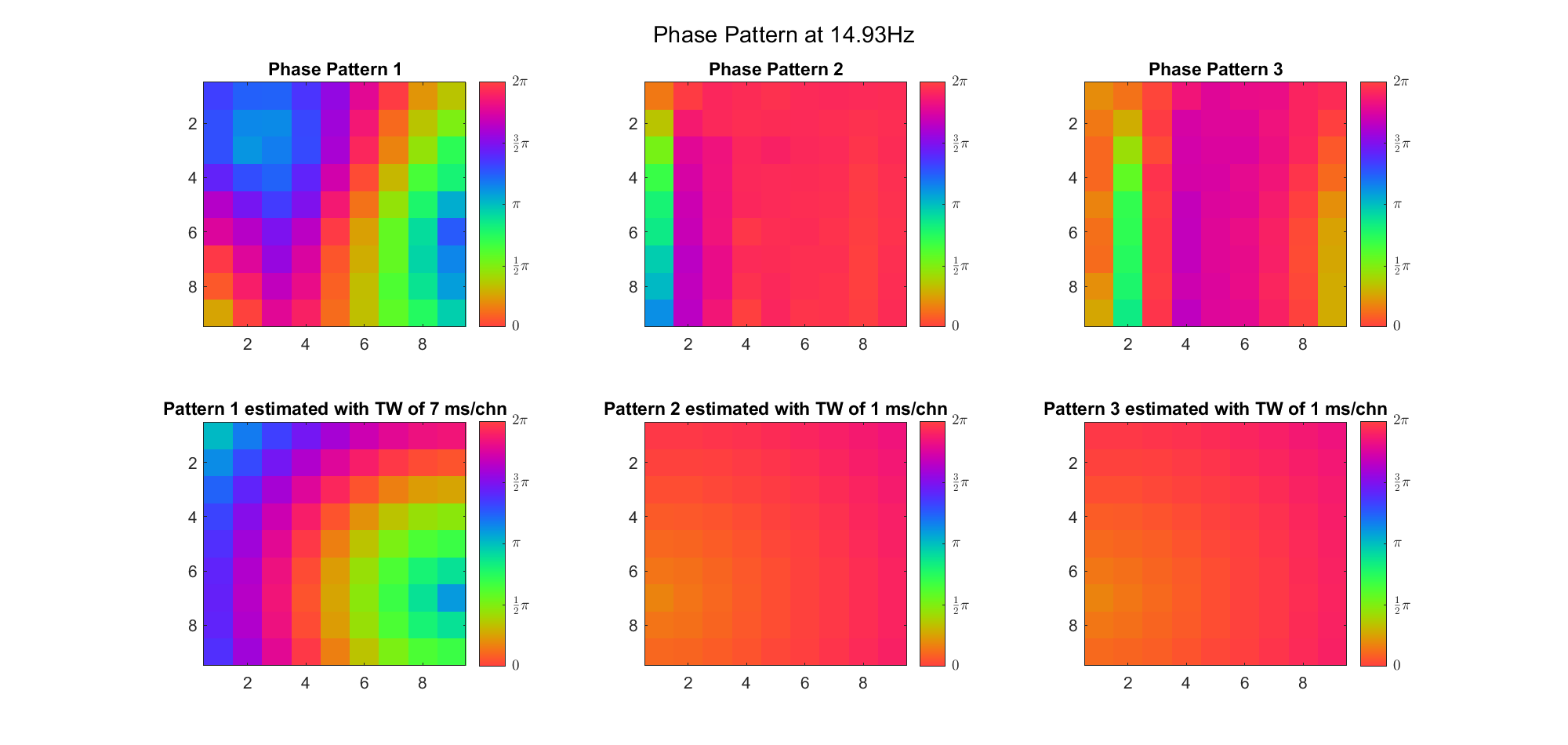 |
Generally speaking, it seems that:
However, when we tried using three possible sources, PCA could hardly find the third source. Here's the result without removing phase offset (ground truth is that the sources were (2, 9), (3, 2) and (8, 6), and speed of TW was 7ms/chn):
| Before Rotation | VariMax Rotation | |
|---|---|---|
| Theta | 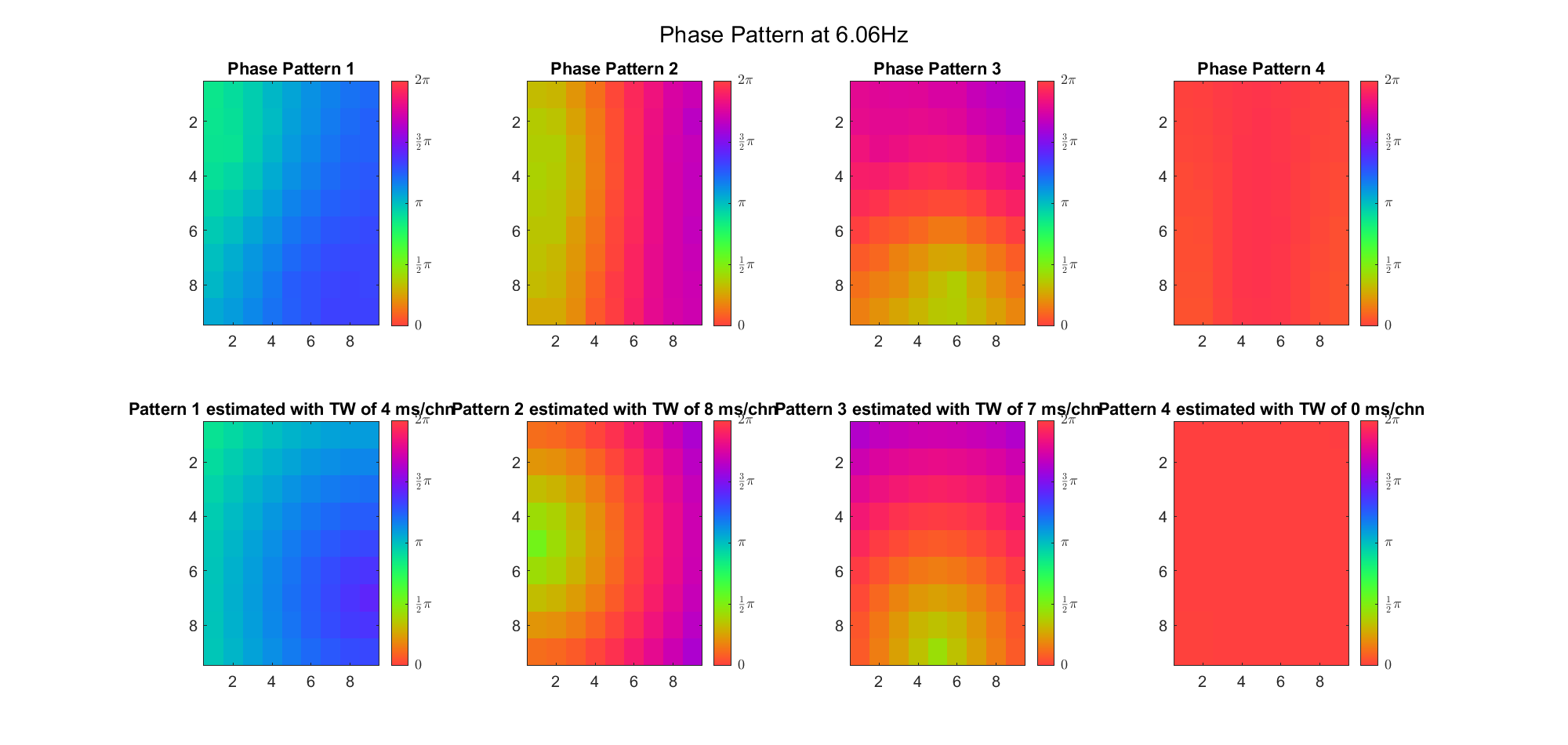 | 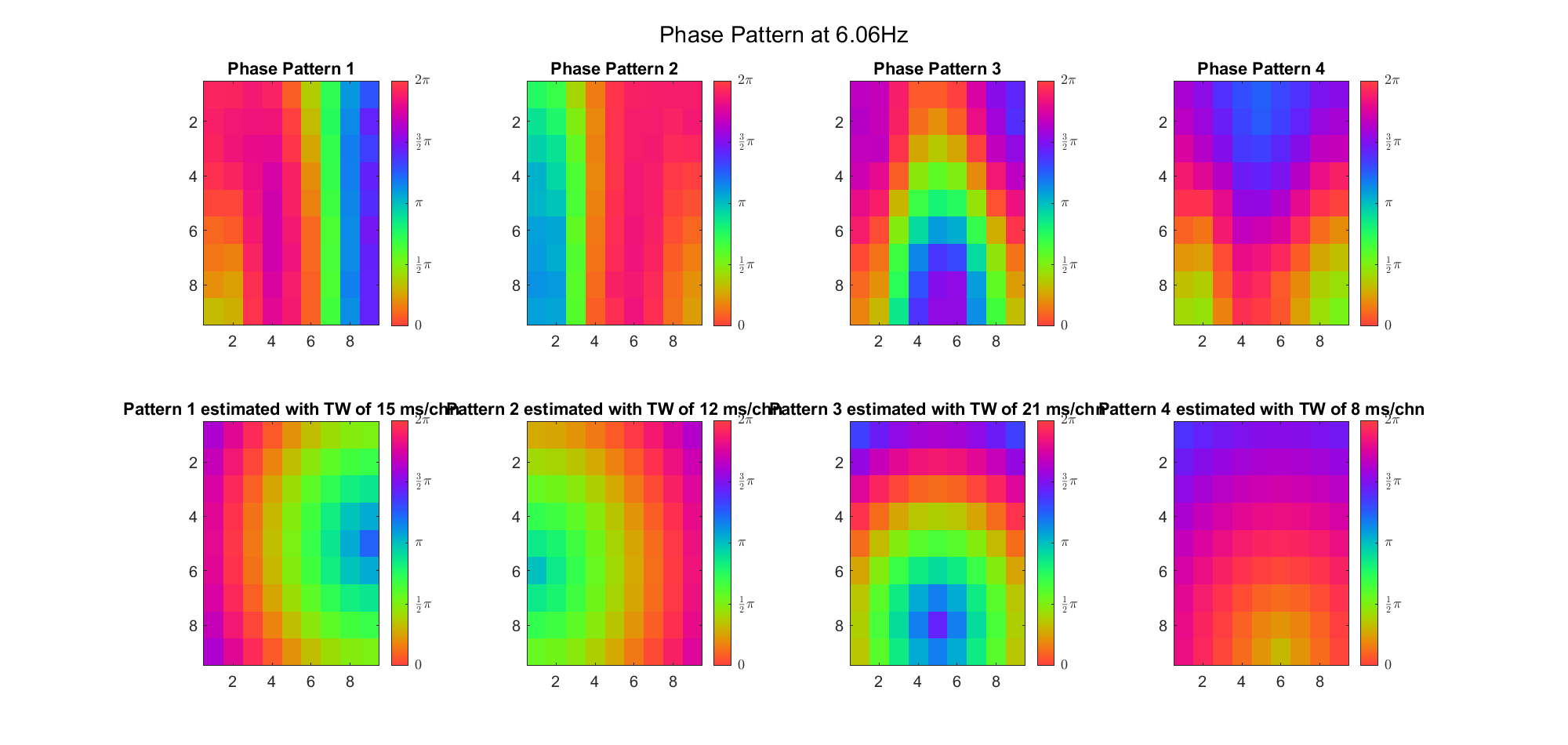 |
| Alpha | 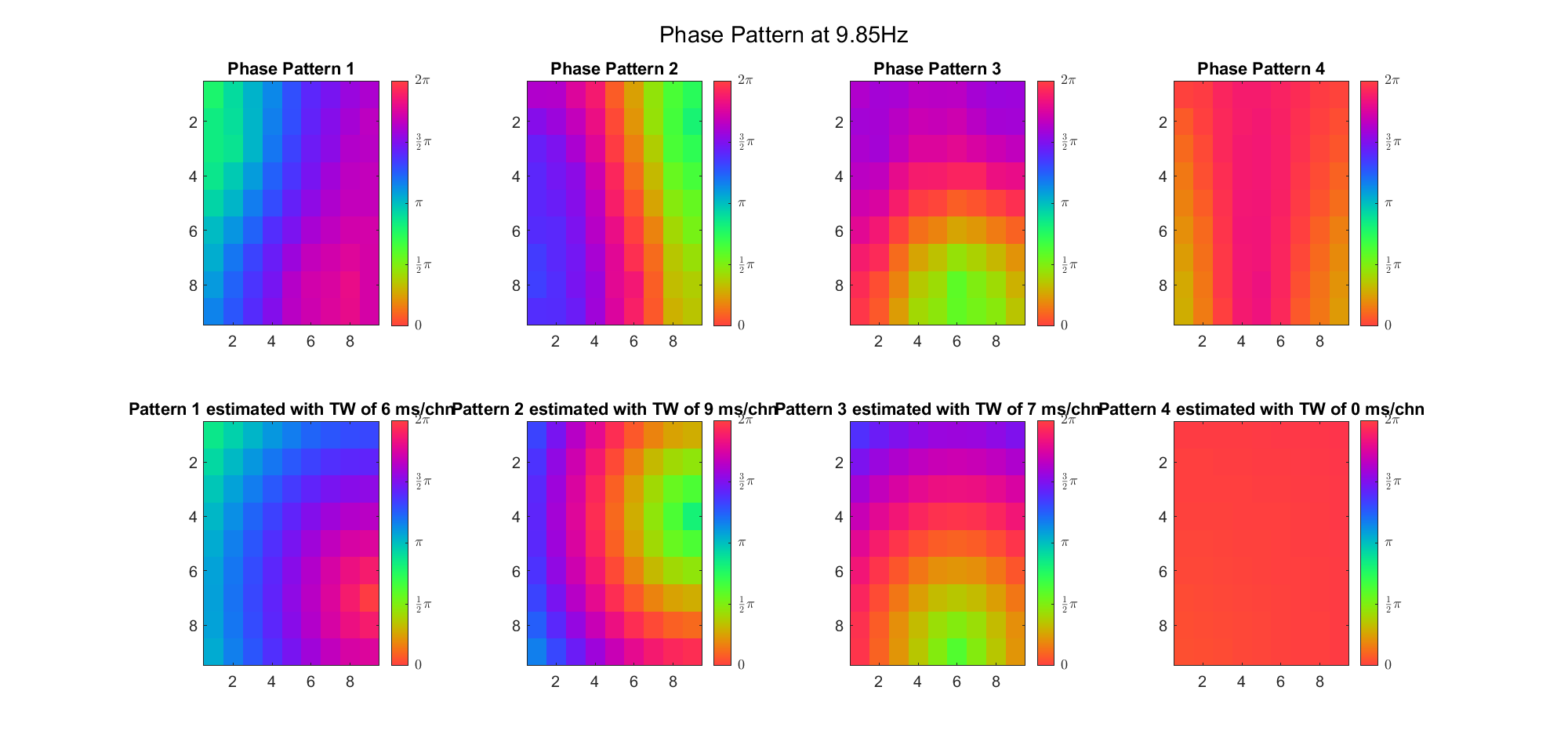 | 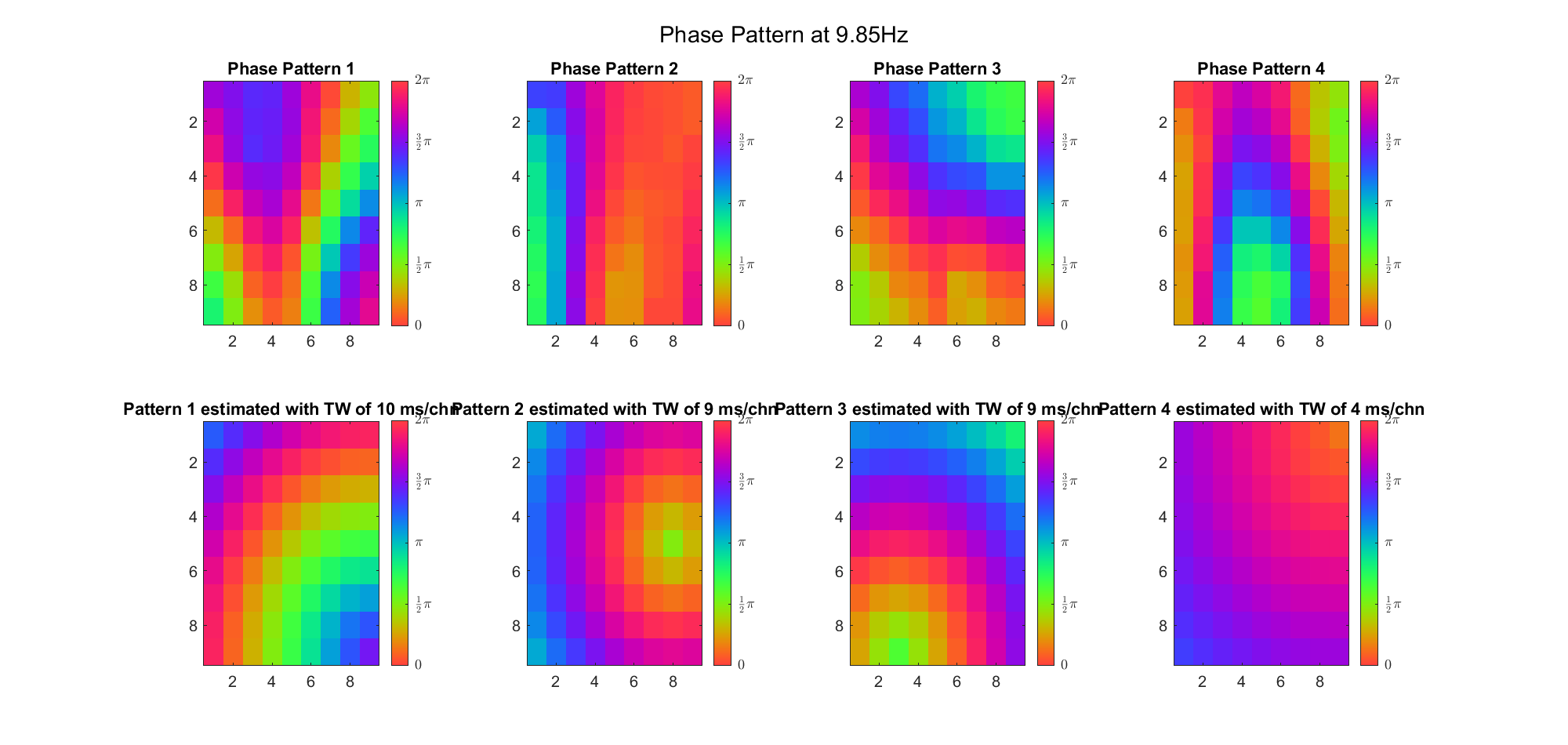 |
| Beta | 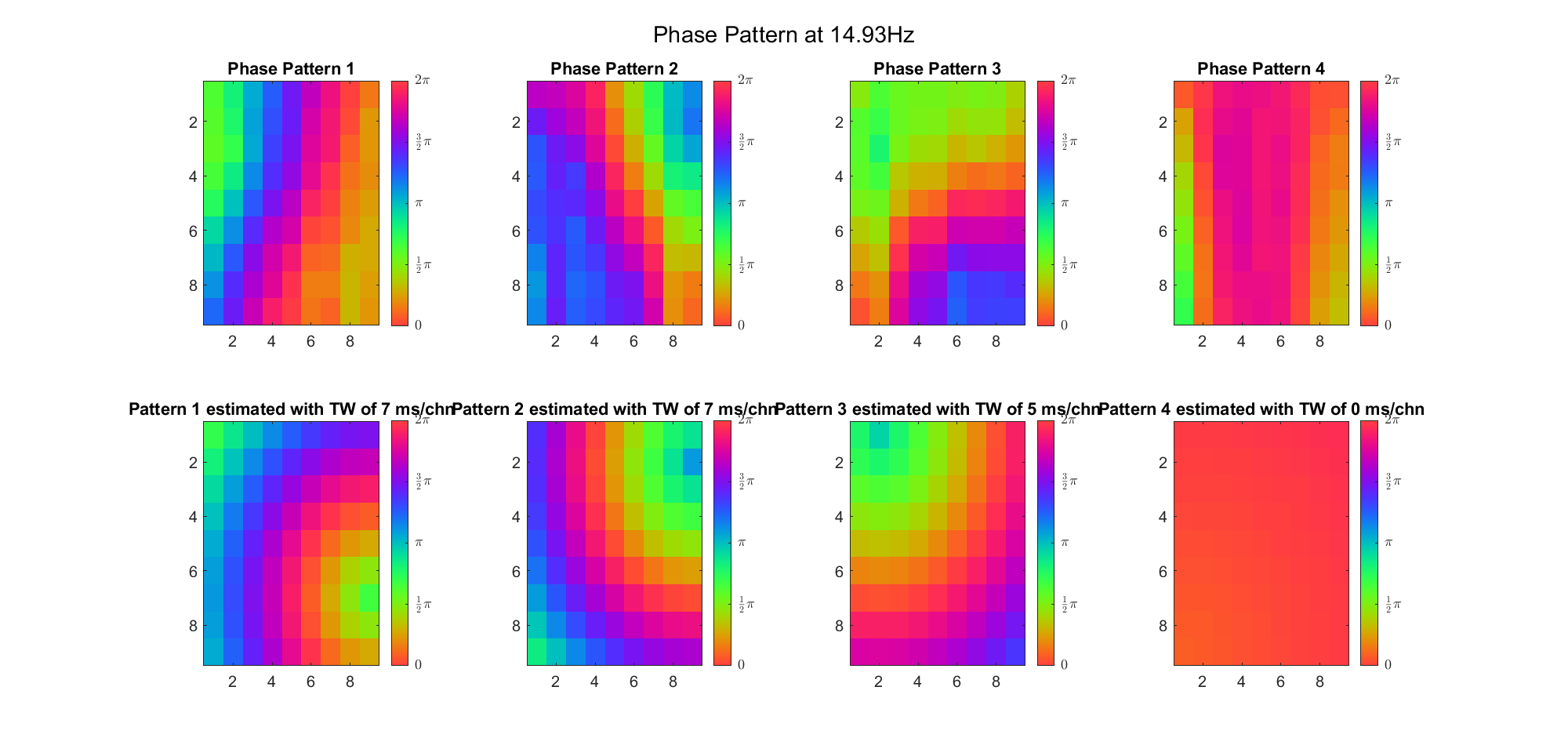 | 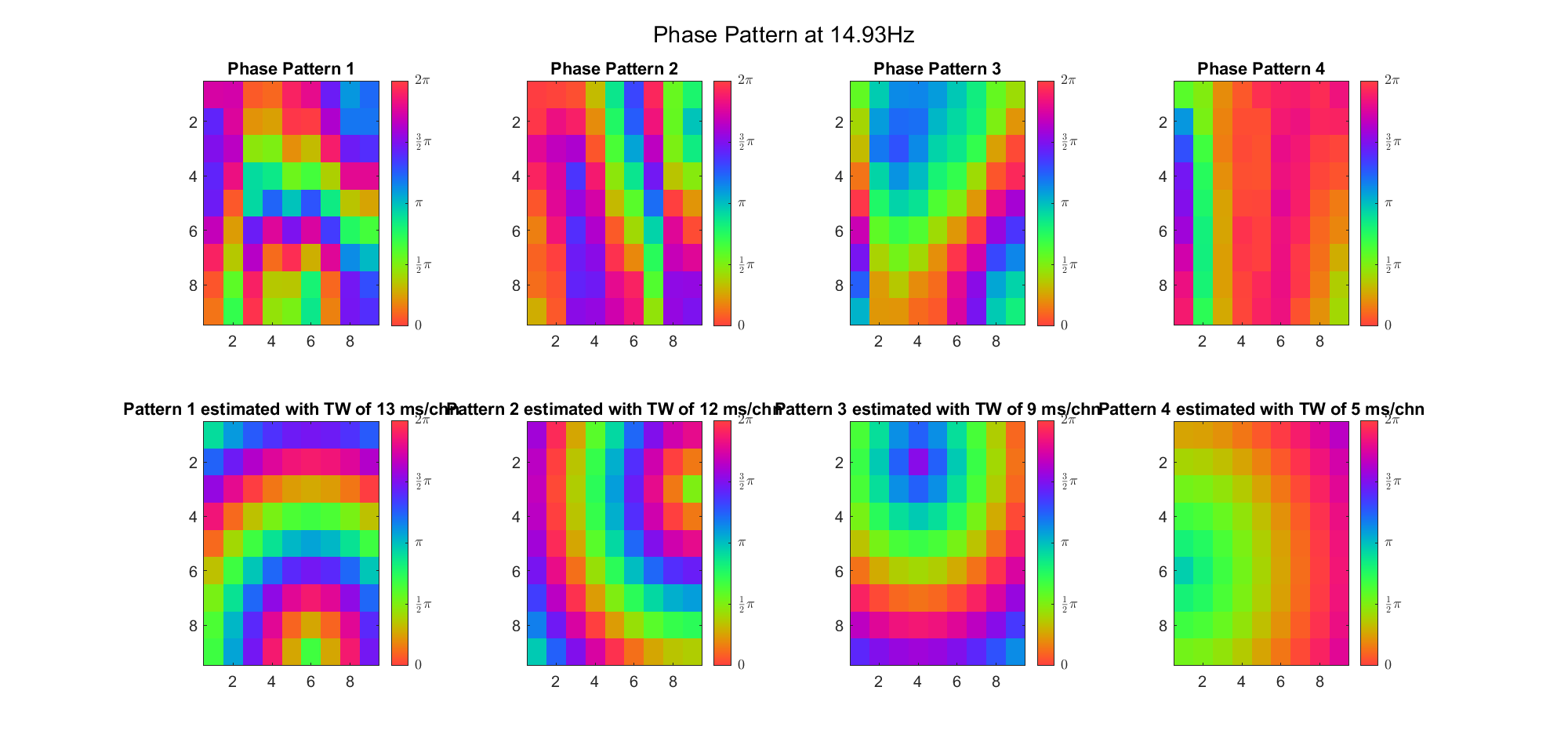 |
Besides, removing phase offset didn't help, e.g for alpha band:
| Before Rotation | VariMax Rotation |
|---|---|
 |  |
Actually this method is very similar to the so-called EEG microstate clustering. The algorithm is roughly the same as the previous one, except that principle components are replaced by cluster centers. One advantage of this method is that we didn't need to scale the component coefficients.
| With Offset | Without Offset | |
|---|---|---|
| Theta | 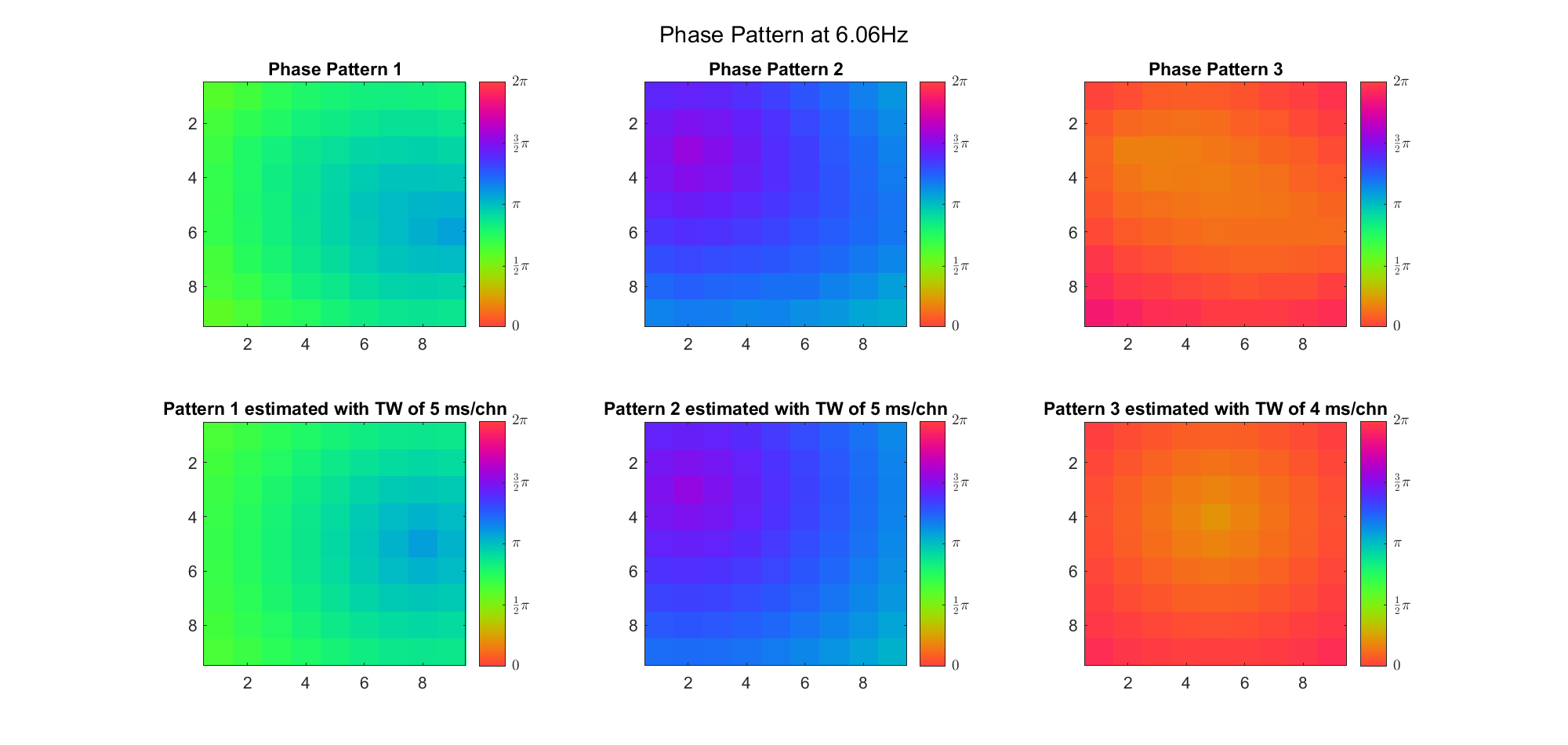 | 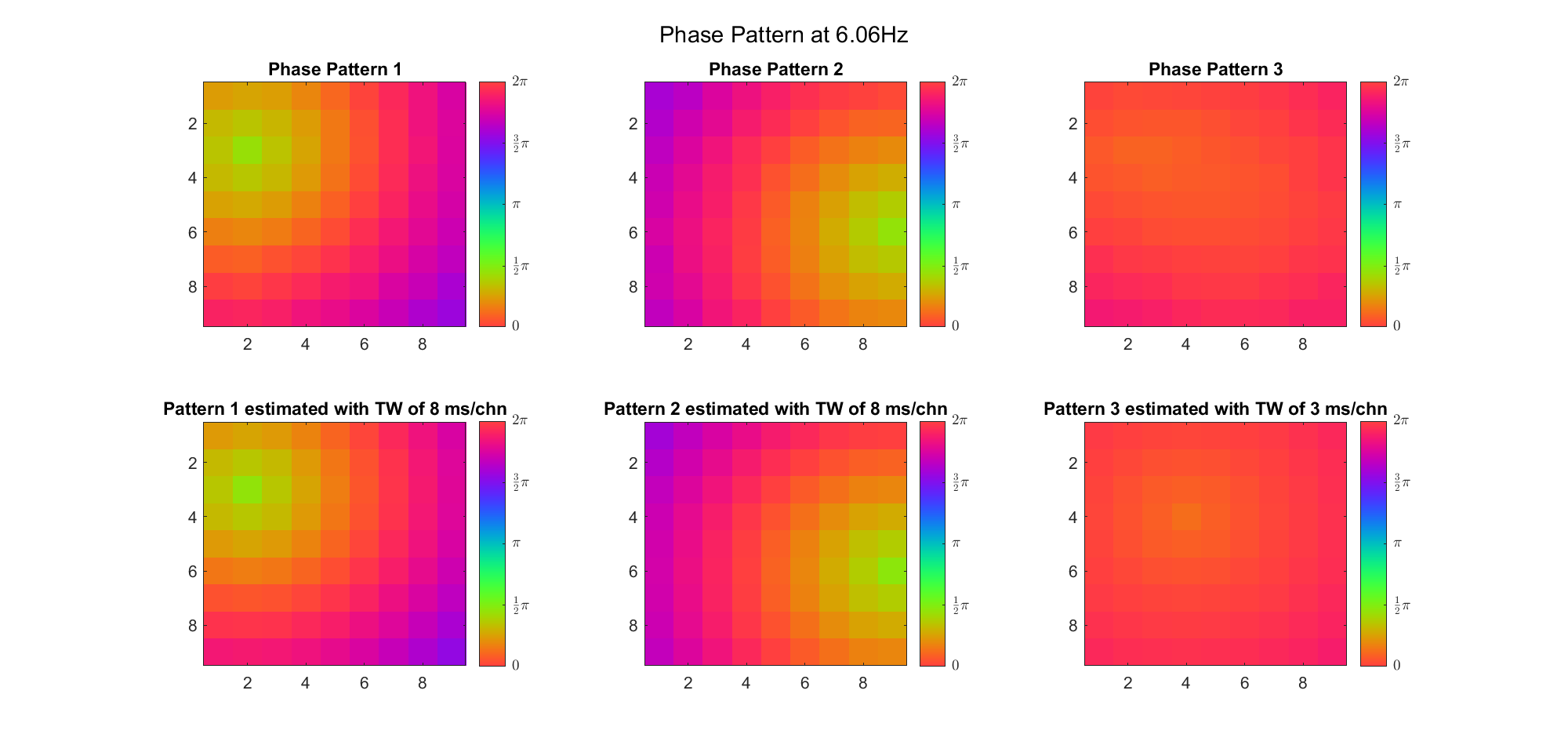 |
| Alpha | 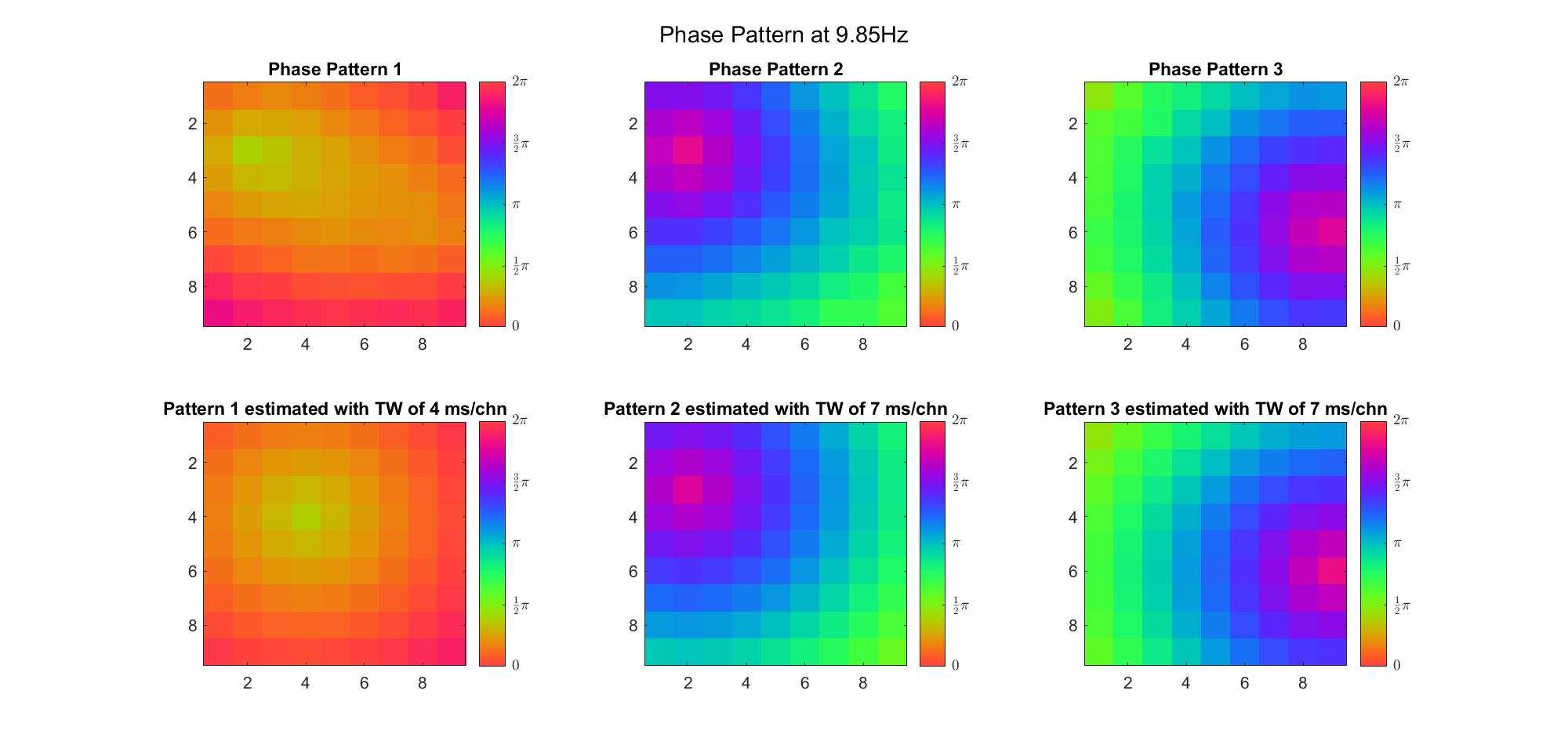 | 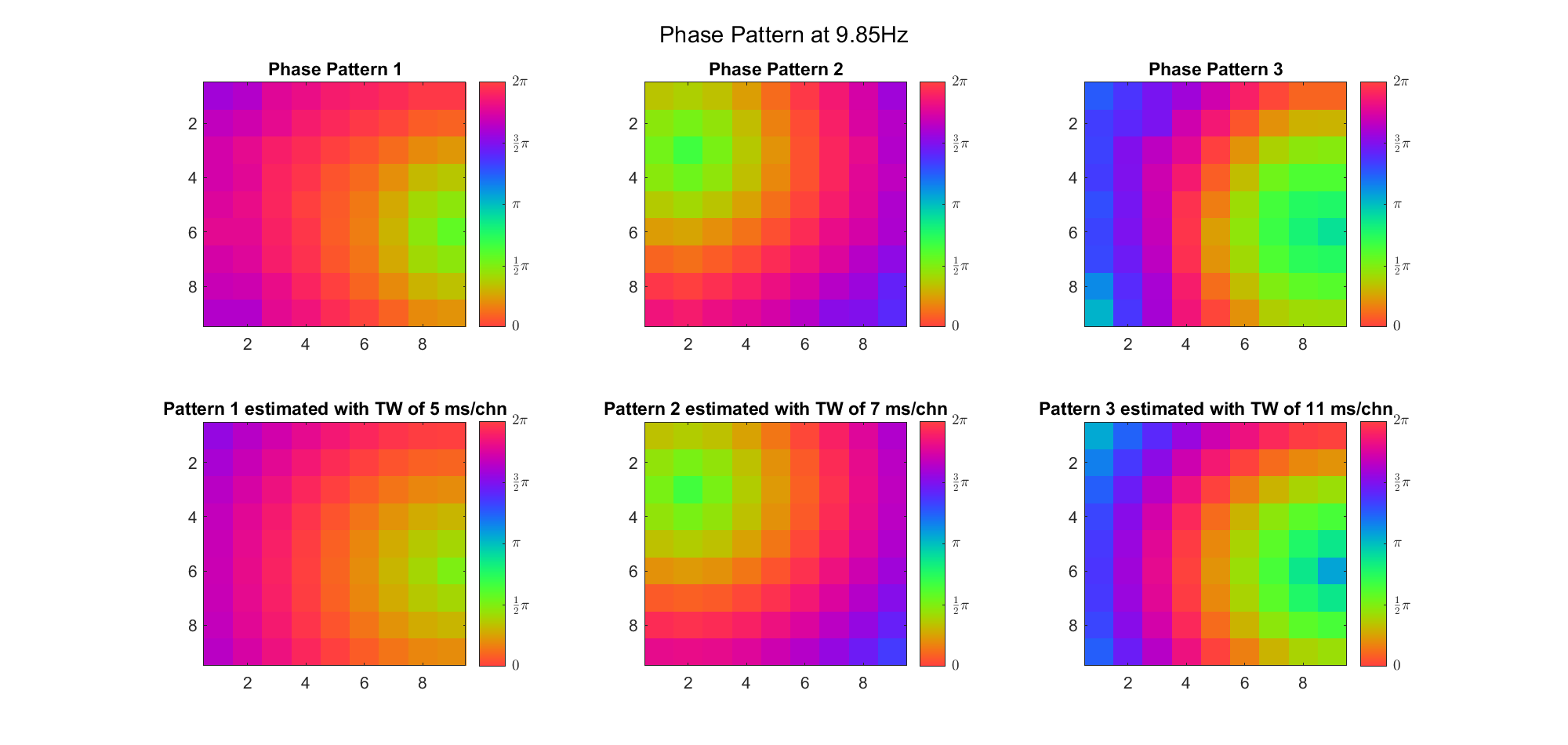 |
| Beta | 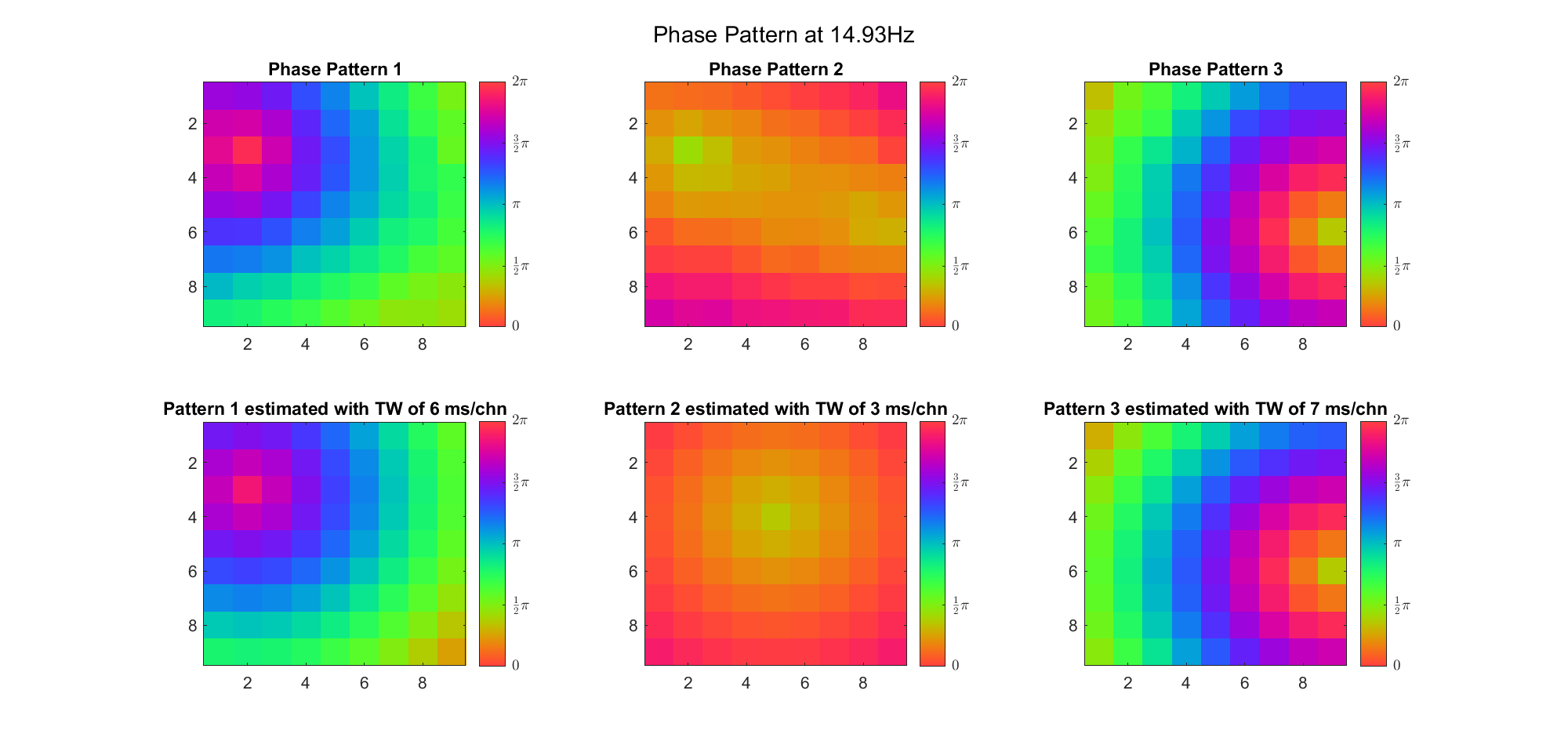 | 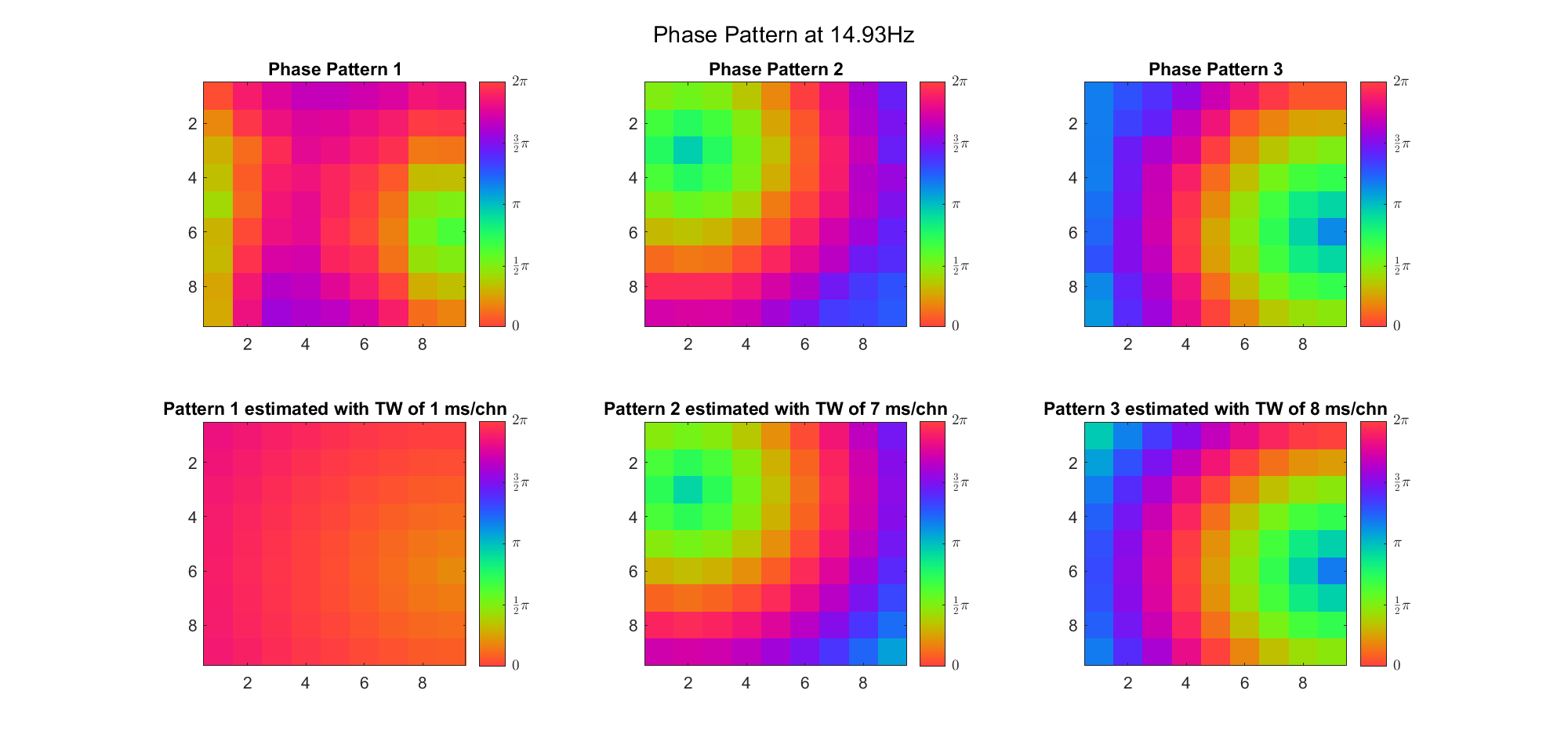 |
Both were excellent, and it seems that removing the phase offset would help exclude the fake clusters.
Increasing the number of possible sources:
| With Offset | Without Offset | |
|---|---|---|
| Theta | 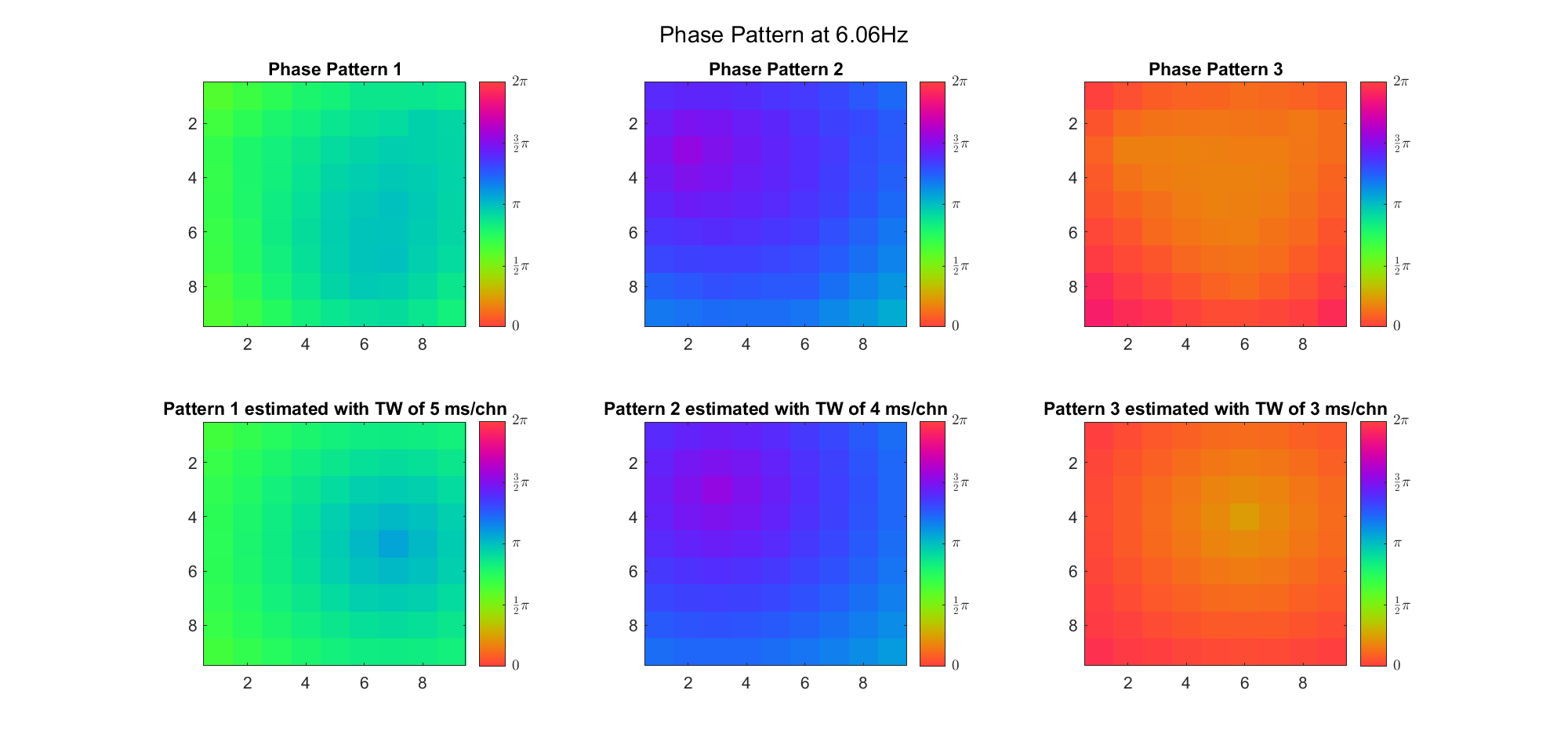 | 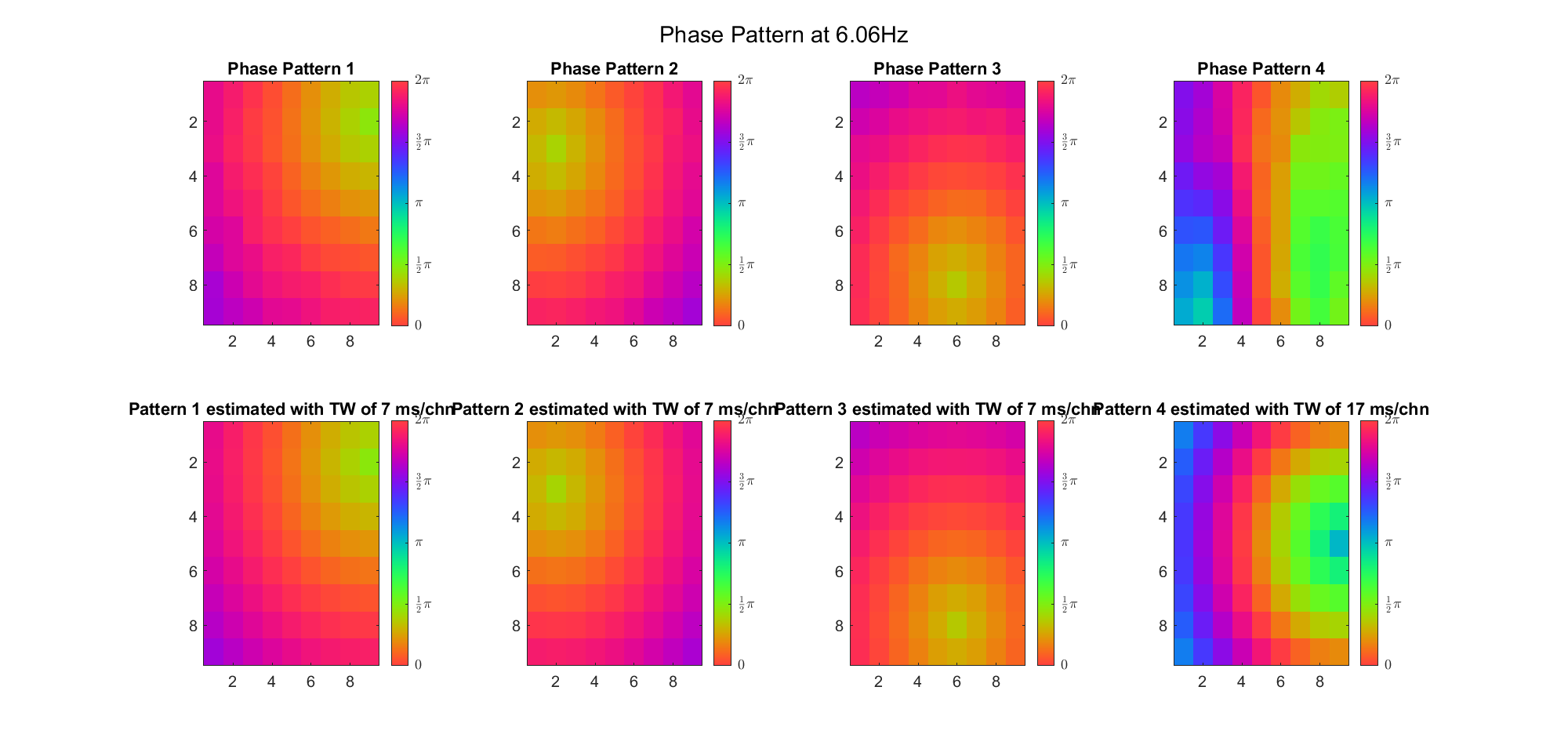 |
| Alpha | 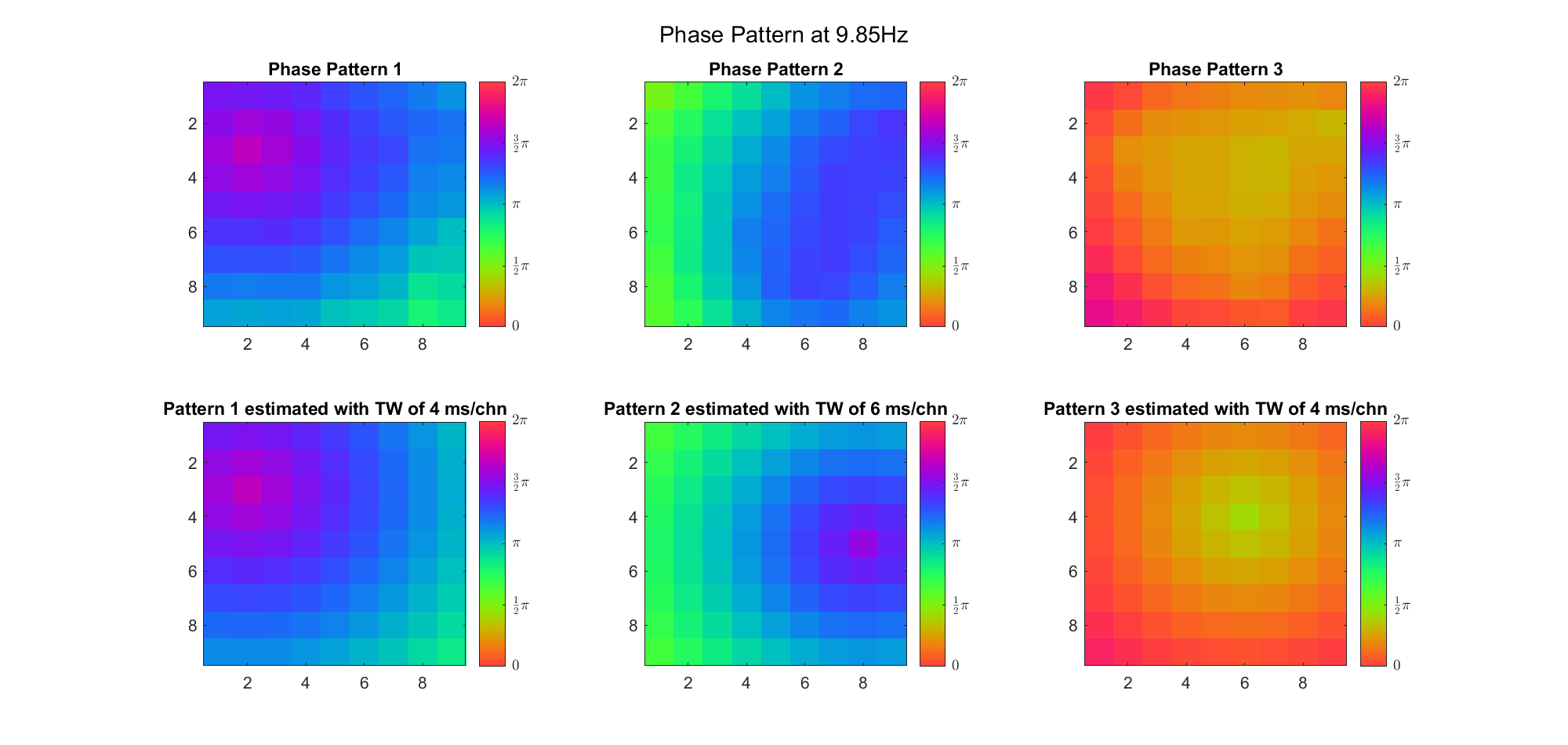 | 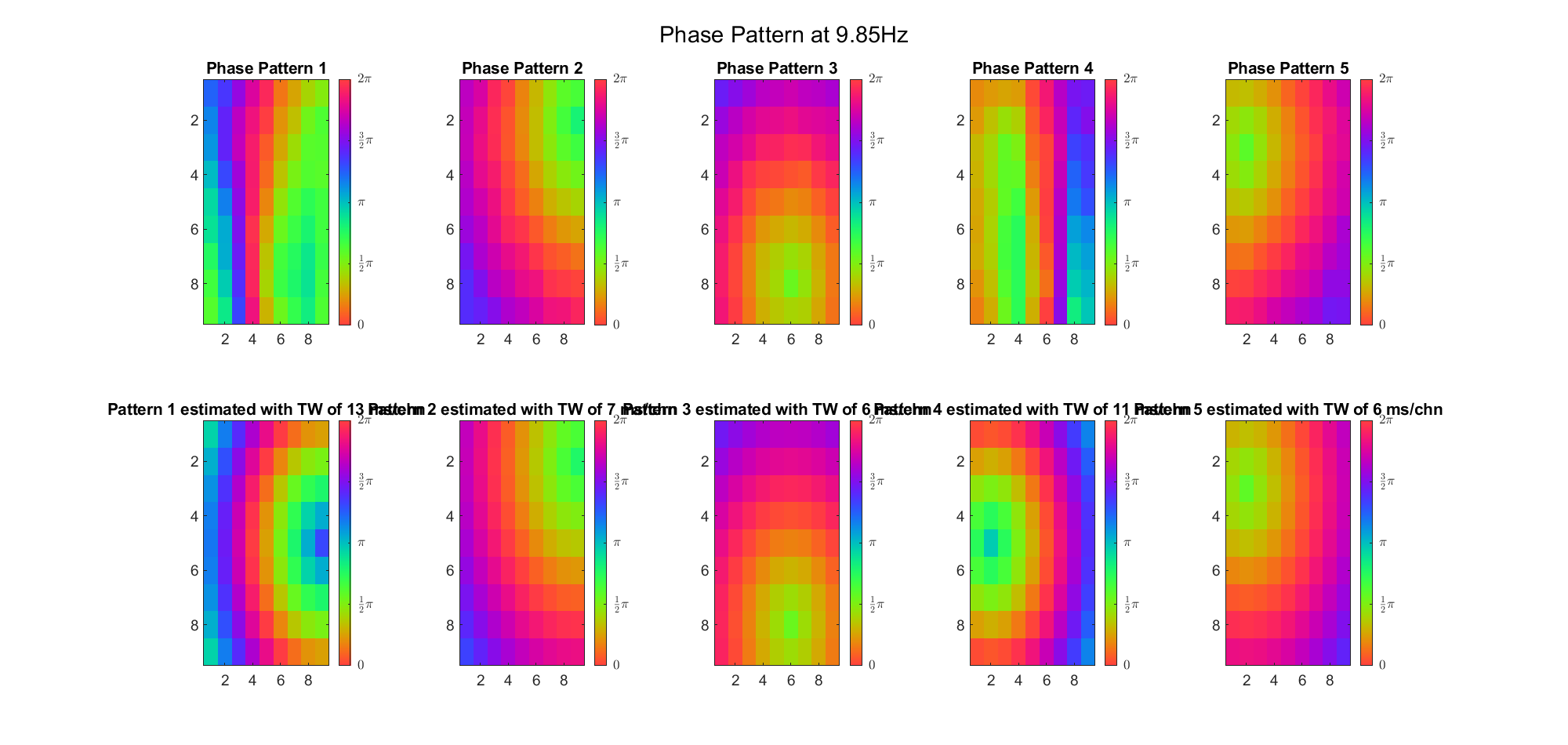 |
| Beta | 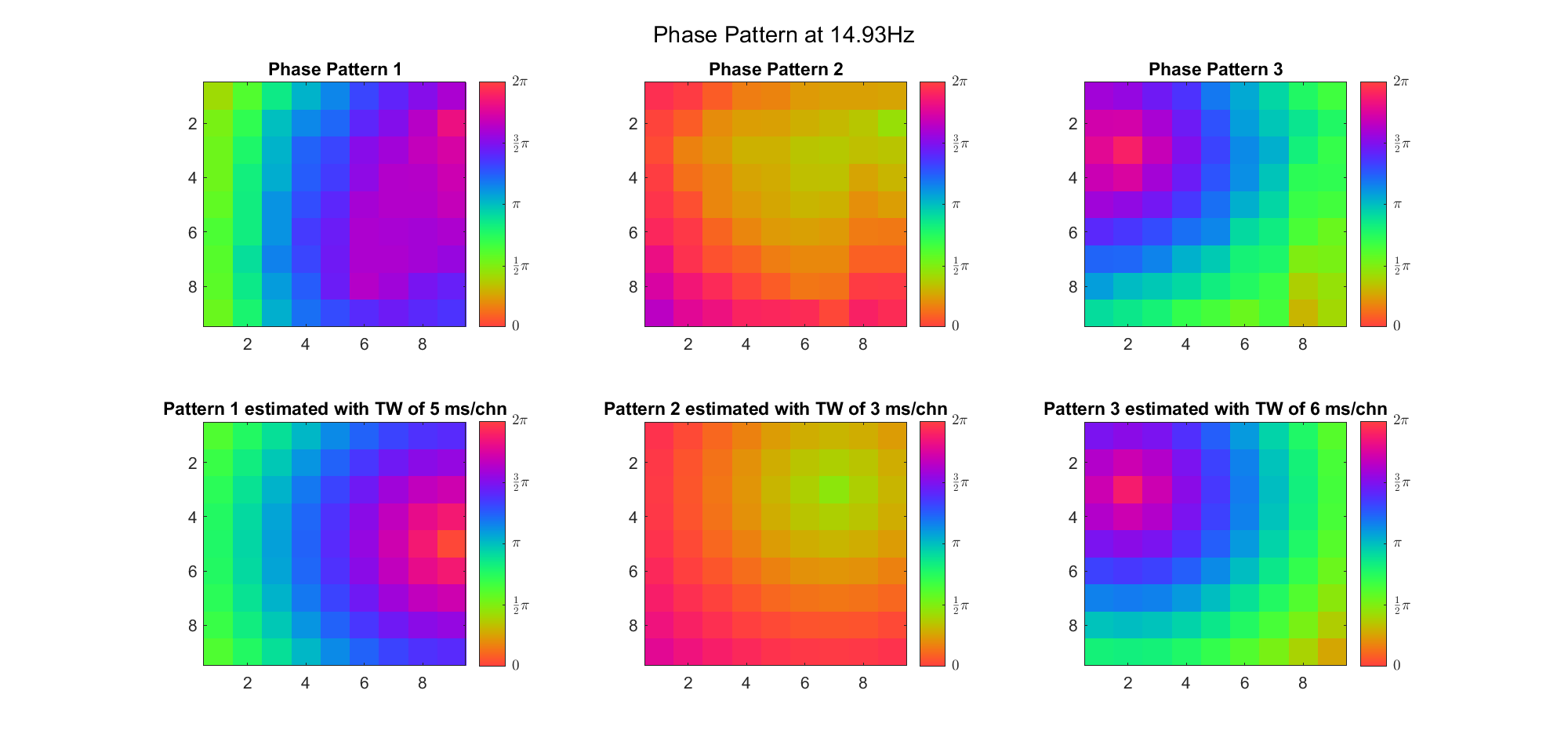 |  |
We can see that k-means could not find the third source (8, 6) either. But after removing the phase lag, the result seems good. However, removing the phase lag will increase the algorithm's sensitivity, so it may generate more clusters than necessary (e.g. for alpha band).
In this part we try to analyze the problem about TWs in a more "mathematic" way, and try to explain why and why not the algorithms performed well.
This is what I got in mind about "travelling waves" before I began to really simulate one:
Namely, the activity at each position is a sine wave, and the phase decreases linearly with the distance between the source and the current position:
However, it becomes less clear when the signal is not a simple sine wave. For example, for a theta-band oscillation, what does it means to describe its "phase" and add "phase lag" to it?
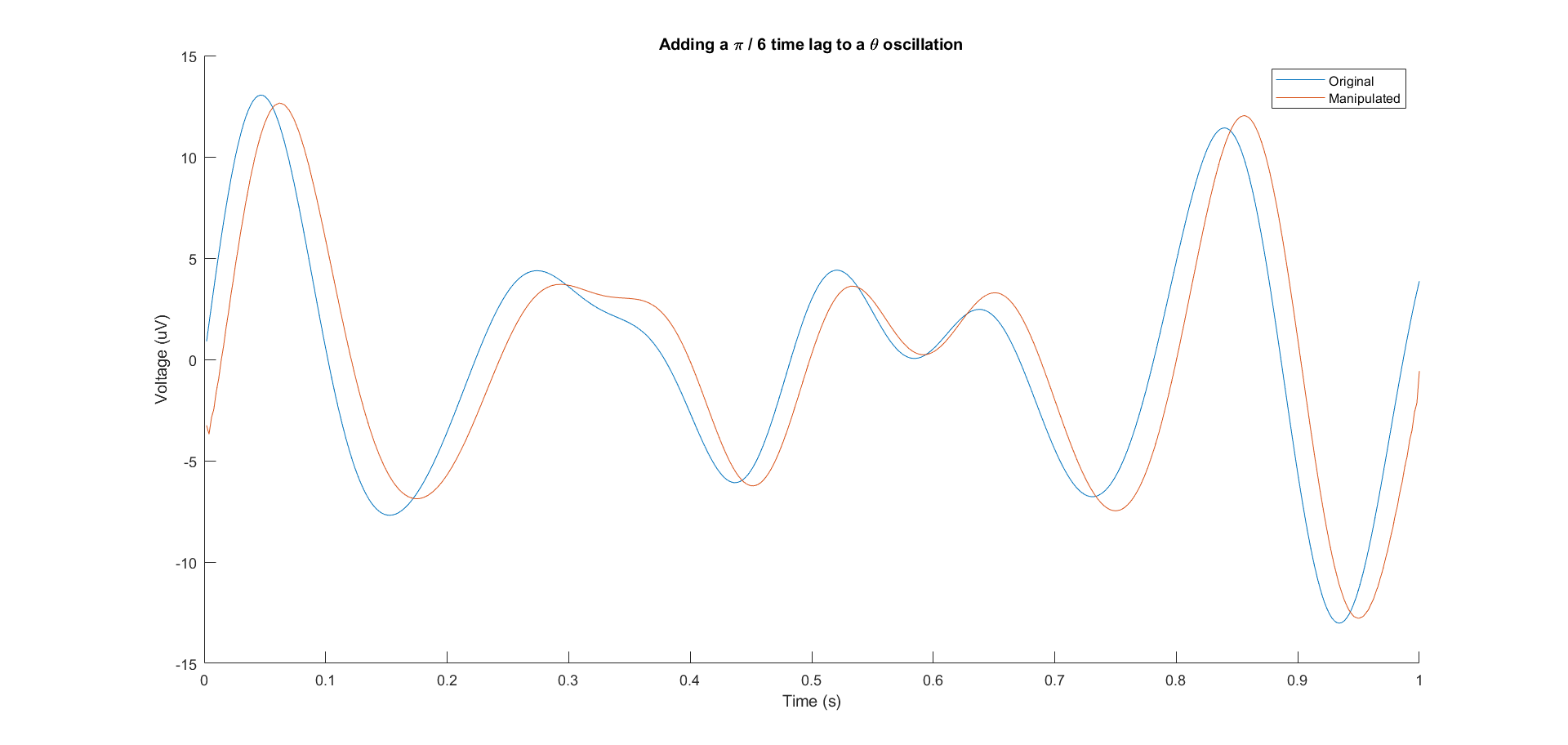
It first reminded me of a famous connectivity criterion called Phase-Lag-Index (PLI), so I reviewed the article and found that the "instantaneous" phase of a narrow-band real-value signal is defined by its analytic representation
(Here are some of my notes)
the Hilbert transform of a signal s(t) is its convolution (in the sense of Cauchy's principle value integral) with the Cauchy kernel
the analytic representation
the analytic representation can be plotted on the polar plain:
Note that the MATLAB function hilbert(x) computes the analytic representation of x rather than the Hilbert transform!!!
But still I didn't understand the relationship between the instantaneous phase and the phases of the frequency components. So I tried to derive what will happen if I add a small lag to the instantaneous phase and extract the real part of the new "analytic" signal as
And we know that if we want to represent a signal as the summation of a series of cosine waves:
Therefore, if we want to determine whether there is a consistent phase lag between A and B, we just need to band-pass-filter the signals, compute the analytic representation and extract the instantaneous phase sequence. Or we can compute the derivative of the sequence and see whether they have similar instantaneous angular frequencies (which indicates a consistent phase difference).
For a given frequency or frequency band, what we try to find are unique TW patterns, each with a different source s (for planar wave, different orientation). So a "perfect" TW phase pattern should be something like
If
rng('default');
C1 = [0 1] + rand(300, 1) * [2 2] + [randn(300, 1) randn(300, 1)] * 0.1;
C2 = [1 0] + rand(300, 1) * [2 2] + [randn(300, 1) randn(300, 1)] * 0.1;
C = [C1; C2];
C = C(randperm(length(C)), :);
idx = kmeans(C, 2);
gscatter(C(:, 1), C(:, 2), idx);
title('Problem of k-means');
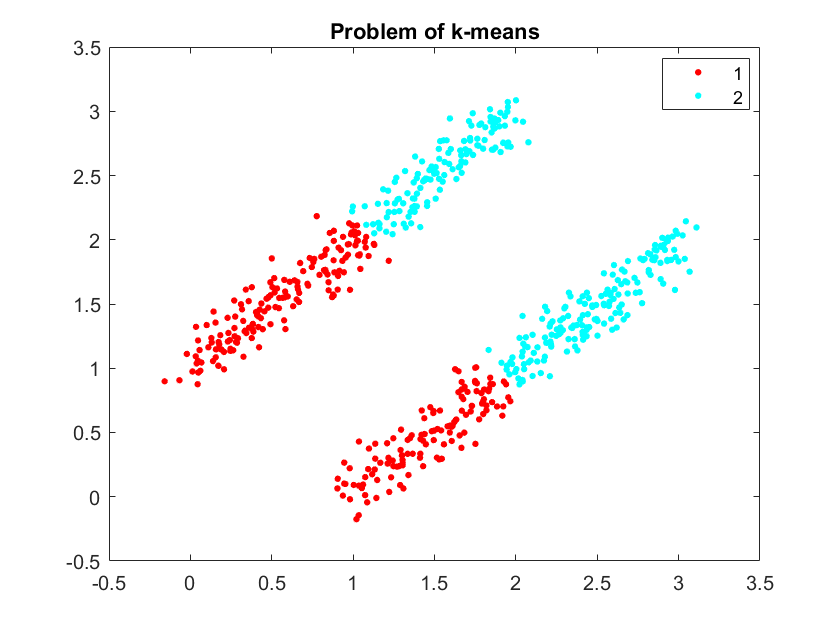
This is consistent with our result in the first and third experiment:
| With Phase Offset | Remove Phase Offset |
|---|---|
 | |
| |
It's clear that with the common phase offset, the algorithm performed worse and the TW structure was distorted.
Actually I don't think the principle components can represent the underlying TW structure, because PCs are the orientations at which the data has a largest variance. If we wish a PC to be something like "distance vector between every channel and the source s", then the variance explained by this PC should actually represents a series of TWs with the same source but different spatial frequency. This is not consistent with our data structure, where most of the variance should lie in [1, 1, 1, ... 1] and something like TW1 - TW2, TW3 - TW2 or so:
rng('default');
C1 = [0 1] + rand(300, 1) * [2 2] + [randn(300, 1) randn(300, 1)] * 0.1;
C2 = [1 0] + rand(300, 1) * [2 2] + [randn(300, 1) randn(300, 1)] * 0.1;
C = [C1; C2];
idx = randperm(length(C));
C = C(idx, :);
x = pca(C);
gscatter(C(:, 1), C(:, 2), 1 + (idx > 300))
hold on;
X1 = mean(C) - x';
X2 = mean(C) + x';
for i = 1:2
plot([X1(i,1) X2(i,1)], [X1(i,2), X2(i,2)])
end
legend({'Cluster 1', 'Cluster 2', 'Component 1', 'Component 2'})
title('PCA');
axis equal
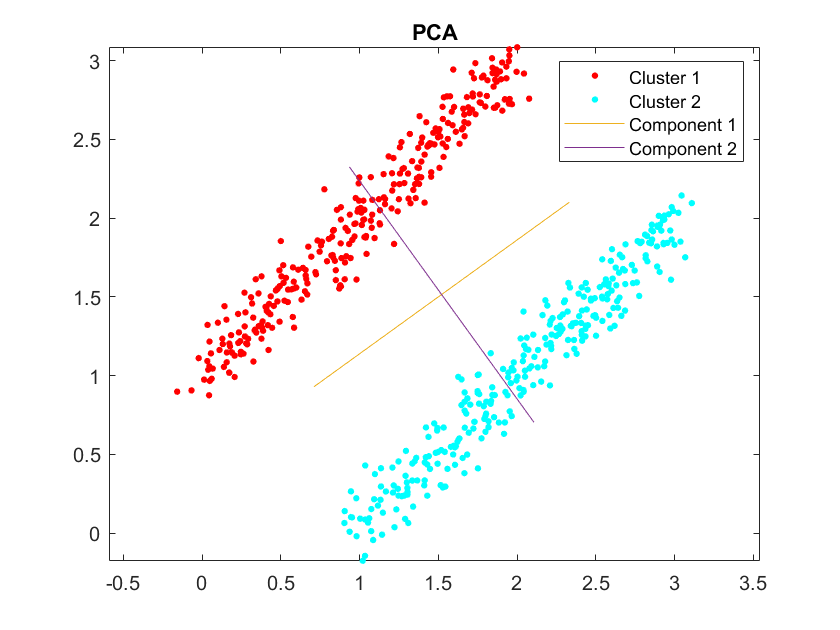
When there are few clusters, maybe we can scale the PCs so that they luckily look like the real TWs (especially when we scale them by the maximum dot product between PC and data sample - as it is in our experiment). But when there are more clusters, it will be hard to find out the TWs in this way. Afrer all, PCA is not a clustering algoithm.
First, we need to try more algorithms. For example, actually we can simply average all samples within each cycle and approximate each of these patterns by a TW, then merge the similar TWs by clustering. We also need to try other methods from the literature.
Second, we need to increase the complexity of TW structures and the level of noise. For example, the TWs may have smaller scope, more possible sources, or even overlap with each other. And we will reduce the SNR by pink noise.
Third, we may use some statistics to quantify the performance of different algorithms, so as to find out the optimal one.
Finally, we may apply these methods to experimental data.
For my second (and more formal) experiment about planar TWs at mesoscopic scale, click here.